type
Post
status
Draft
date
Jan 9, 2026 11:44
slug
rl
summary
tags
reinforcement-learning
TD
DQN
PPO
category
工具
icon
password
文本
学习点:
基础知识
- 强化学习的基本框架(状态、动作、奖励、策略、价值函数) 观测值:随机变量的实际数值 随机变量:基于随机事件的随机数 随机抽样 颜色是随机变量
重点:
状态和动作
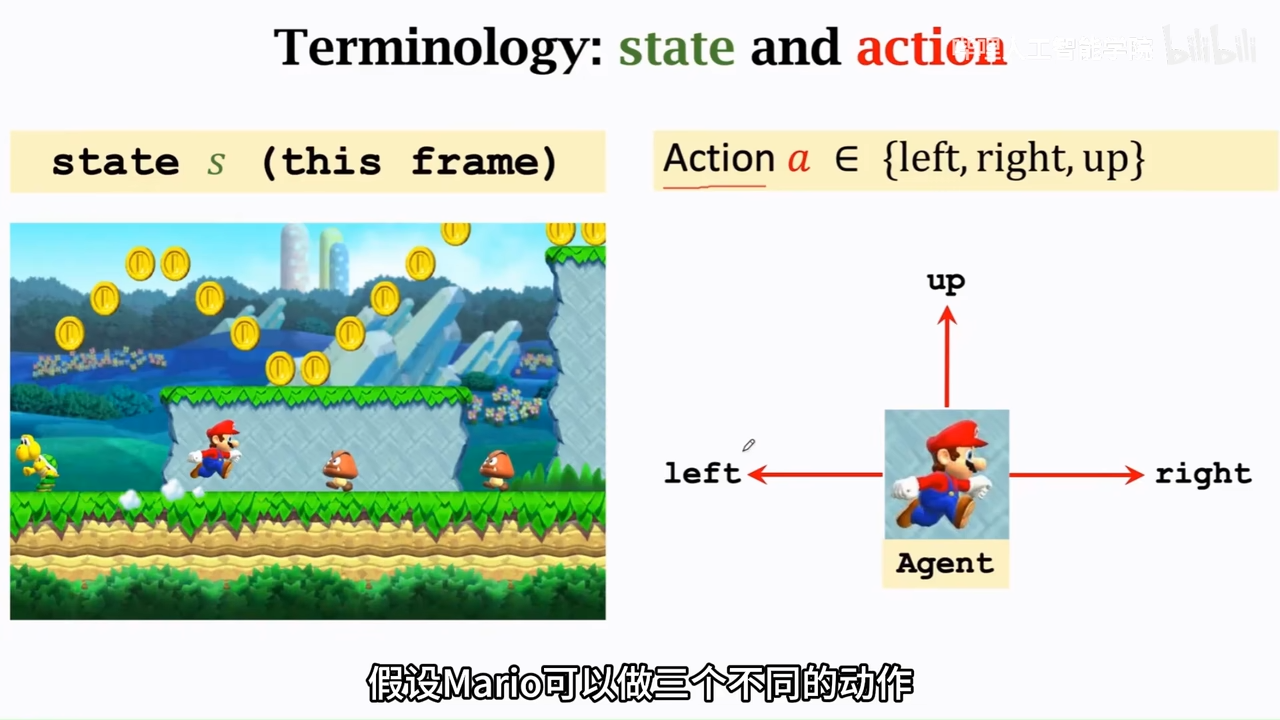
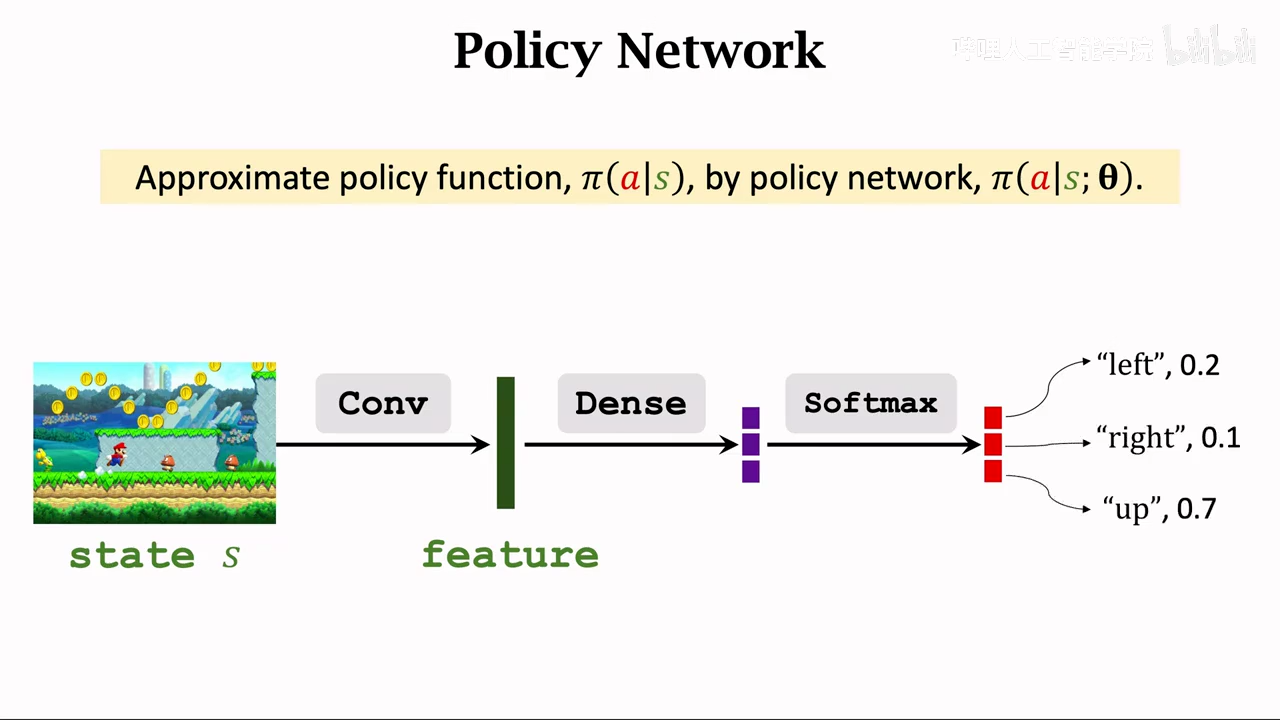
当前游戏界面可以被叫做state
可以操作的游戏主人公是agent
动作是谁做的设就是agent
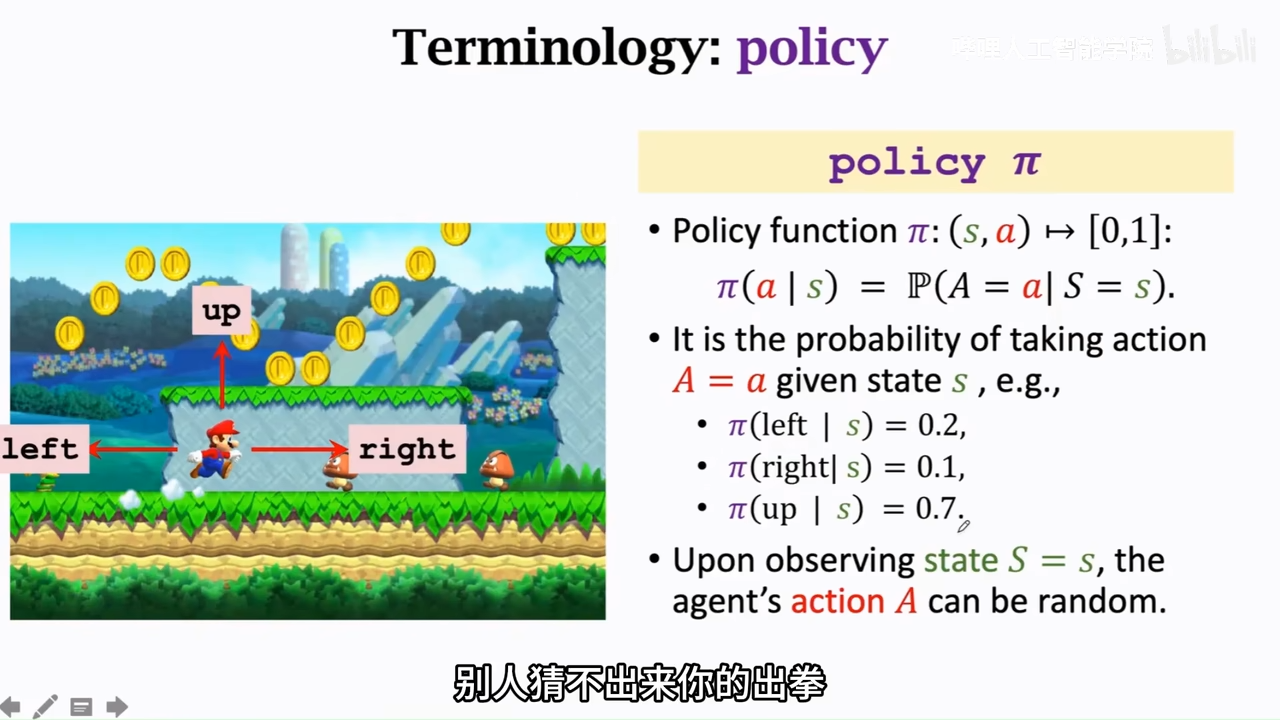
policy 策略,根据state,做决策控制agent的action
强化学习的重点就是学习policy
agent的动作是随机的,是根据policy中各个动作的概率来做动作
奖励reward

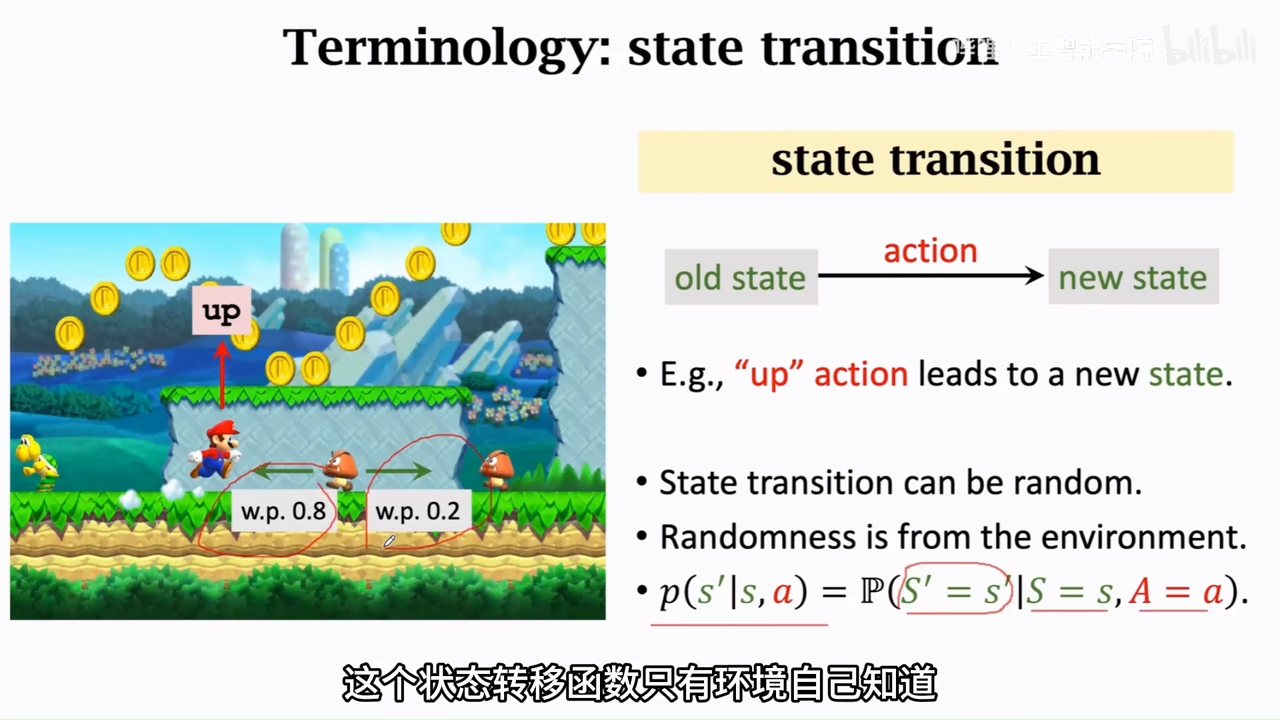
状态转移函数
马里奥例子中的状态转移函数未,在当前状态,动作向上跳的情况下,下个一时刻的状态如何,但是由于环境也有随机性,所以这个概率密度函数(状态转移函数对于agent是未知的)
rl中随机性的来源
- 动作随机性(agent随机),动作是基于policy函数随机输出的
- 动作转移随机性(环境随机),当前动作执行之后,加上环境的随机变化,会导致当前状态也是随机的
重点容易混淆概念
return/reward
return
未来累计奖励
折扣回报
这里的γ是超参数,


这里的return的随机性来源和rl中的随机性一样

- 动作随机性
- 状态随机性 导致return跟未来的所有时刻都有关
Ut是一个随机变量,与未来的所有时间相关,所以可以通过积分,将未来的时间进行积分
对 求期望就可以把随机性去掉
也就是得到一个事件发生的概率,这个就是价值函数
动作价值函数


Q_pi 的值跟policy pi有关
Q* 表示当前状态,可以直接告诉我们at这个动作的评分,与pi无关,通过max,将pi去掉,
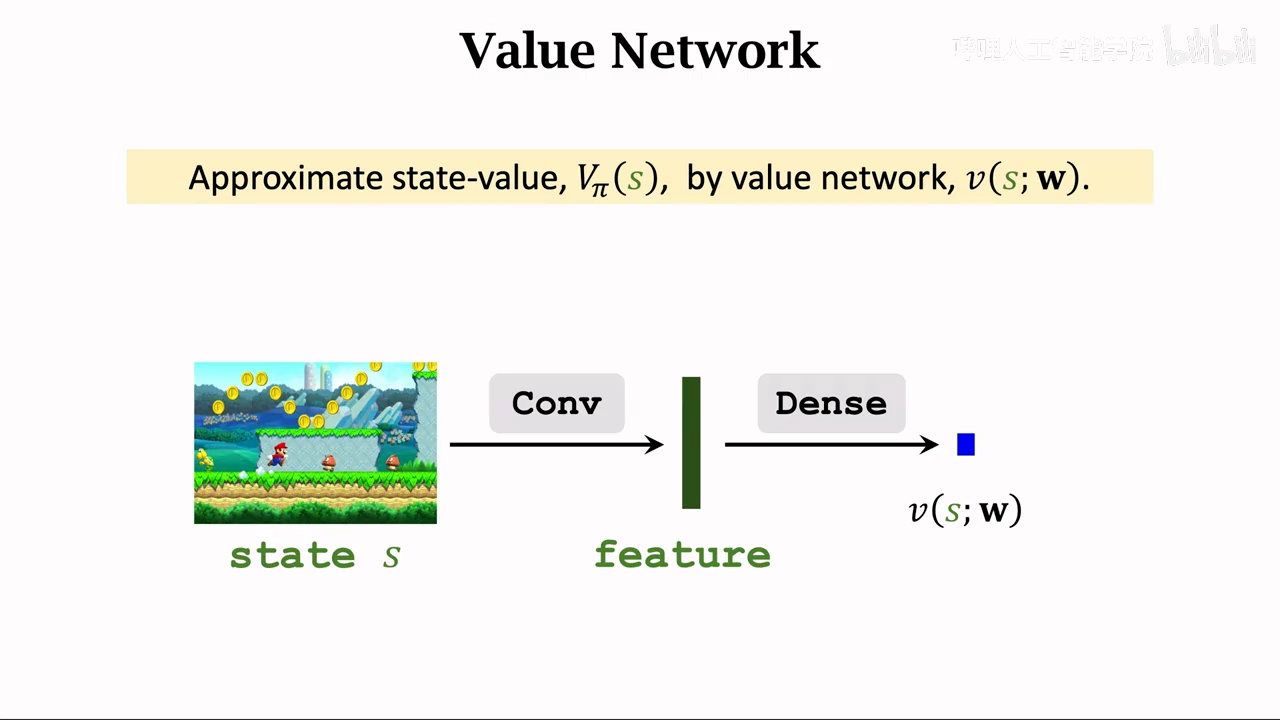
状态价值函数
这里的A是随机变量,通过求期望,将A去掉,导致Vpi只与St、pi有关


总结

实际应用
- policy base learning 选择一个好的策略,当前状态作为输入,pi policy 输出下一个各个动作的概率,随机采样,选择一个动作输出
- optimal action-value function 同样当前状态作为输入,不过会引入所有的动作进行打分,最后选择分数最高的动作执行 强化学习的核心就是学习pi函数或者Q* 函数
总结
oavf:可以评价当前at的好坏
svf:可以评价St、pi的好坏

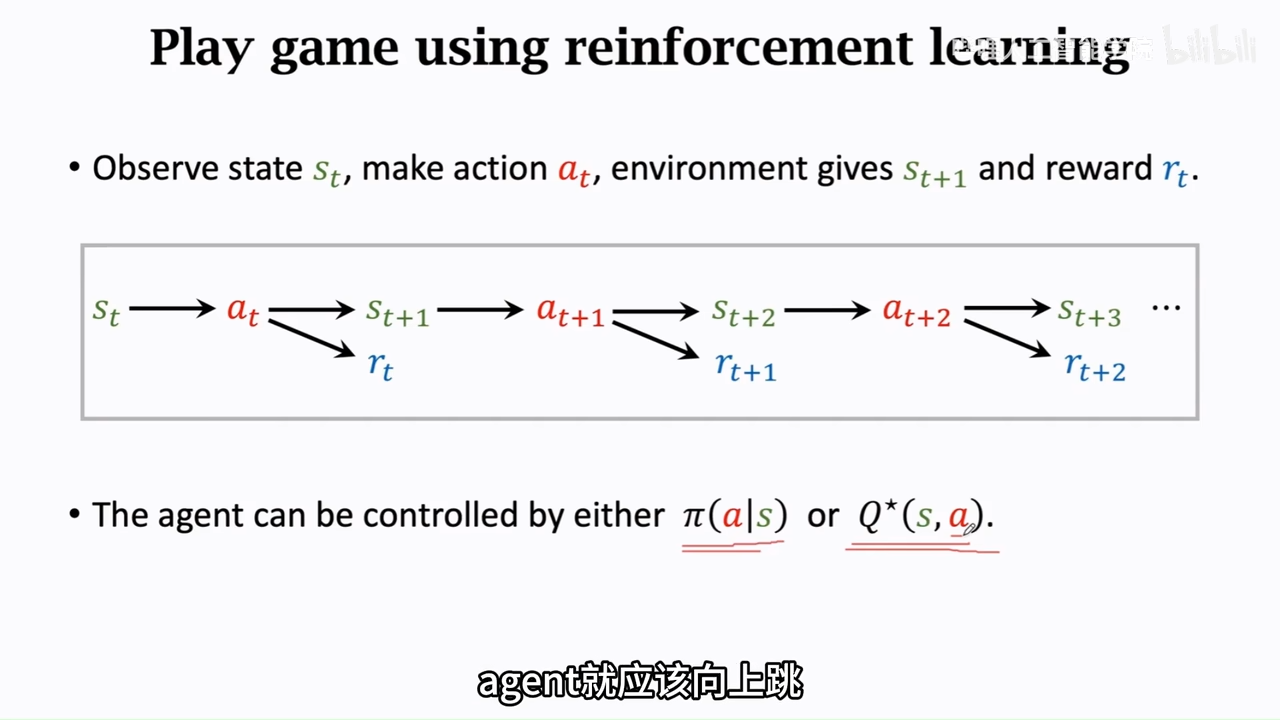
value base learning

- 动作随机性来源于 pi函数
- 状态随机性来源于 p函数
TD算法深入学习



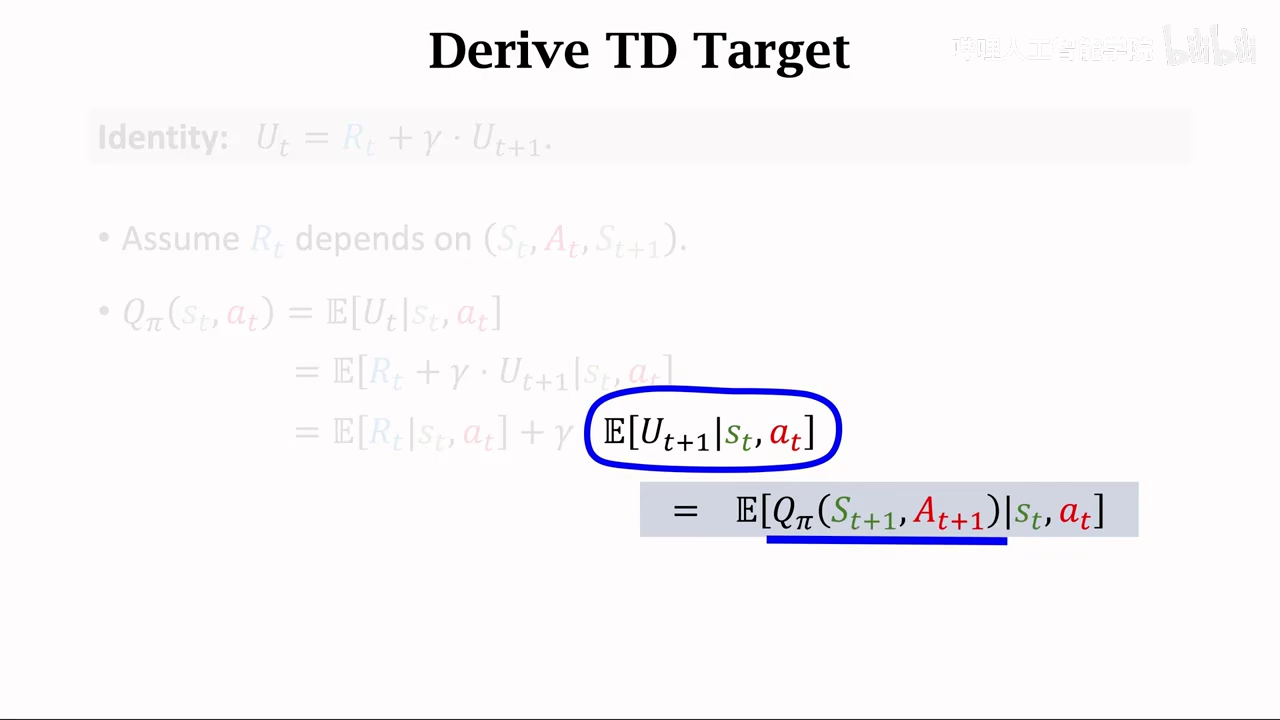
这里做了一个蒙特卡洛近似,也就是从概率值变成的采样值
yt部分基于实际值,
所以TD算法其实就是让Qpi逼近yt


sarsa
sarsa表格形式
sarsa算法即更新表格中的数值



神经网络板sarsa
得到的近似Qpi的神经网络被称为价值网络



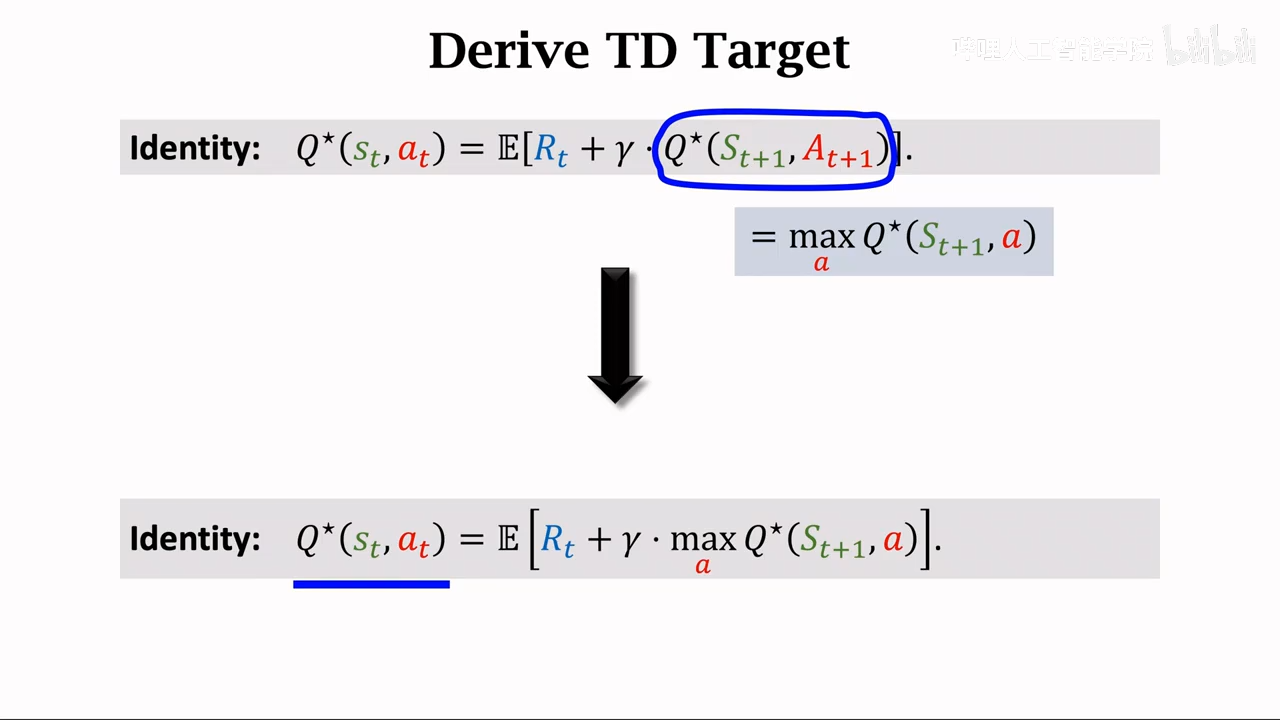
Q-learning
也是学习Qpi
学习最优动作函数Q*
即DQN所使用的TD算法
主要区别就是这里使用的一个最大化的Qpi 也就是Q*




遇到比较难计算的期望,使用蒙特卡洛进行近似计算
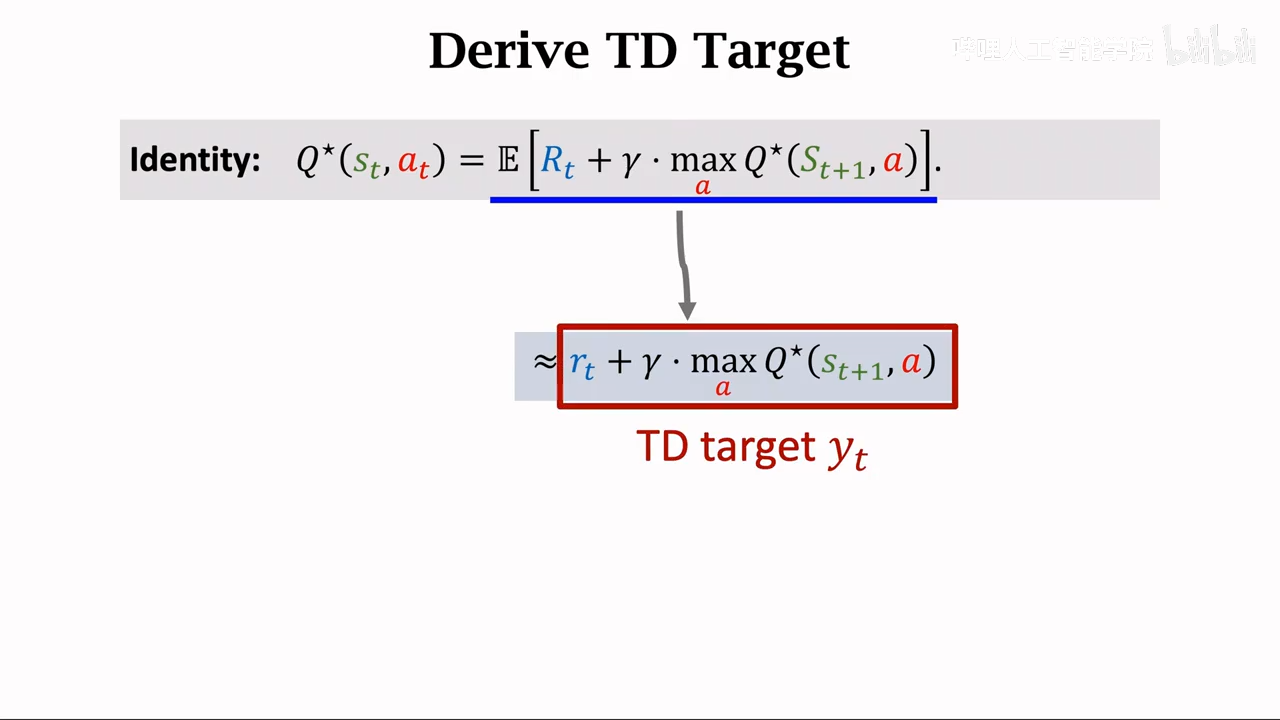
表格形式

神经网络形式
其实和sarsa没啥区别

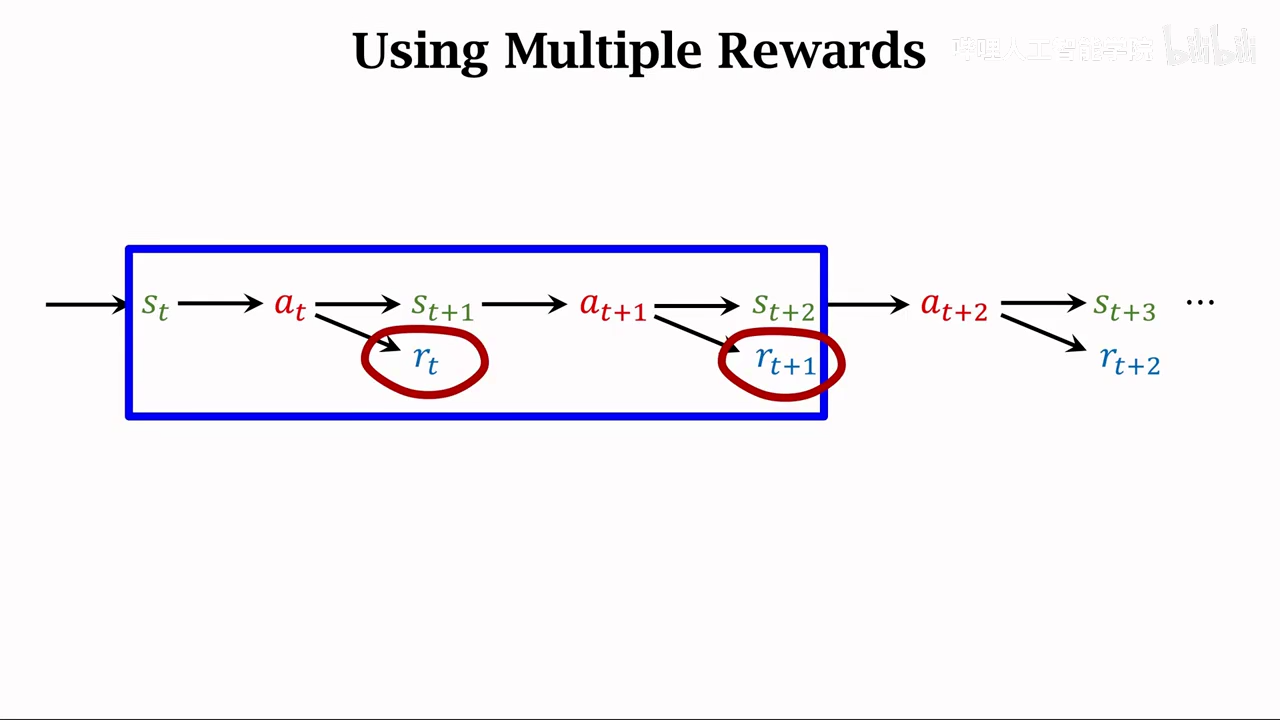
multi-step TD target
这个方法专注于优化TD target,可应用到sarsa、Q-learning上

基于多个时间的reward来计算TD target就是multiple-step TD target




主角DQN
Q* 预测未来
但实际上无法获得准确的Q*
价值学习本质上就是在你和Q*
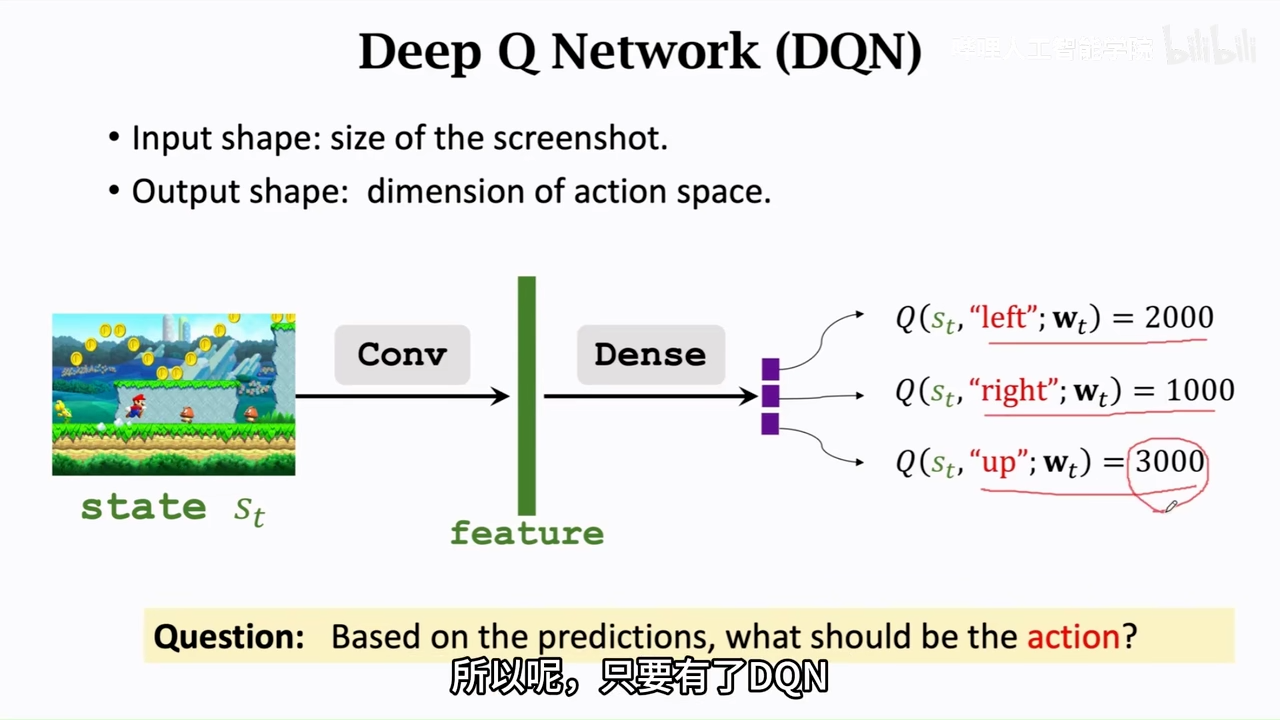
DQN
使用一个神经网络来近似Q*
Q(s,a;w)
网络参数w
网络输入s,a
网络输出,对于a(动作)的打分

实际应用
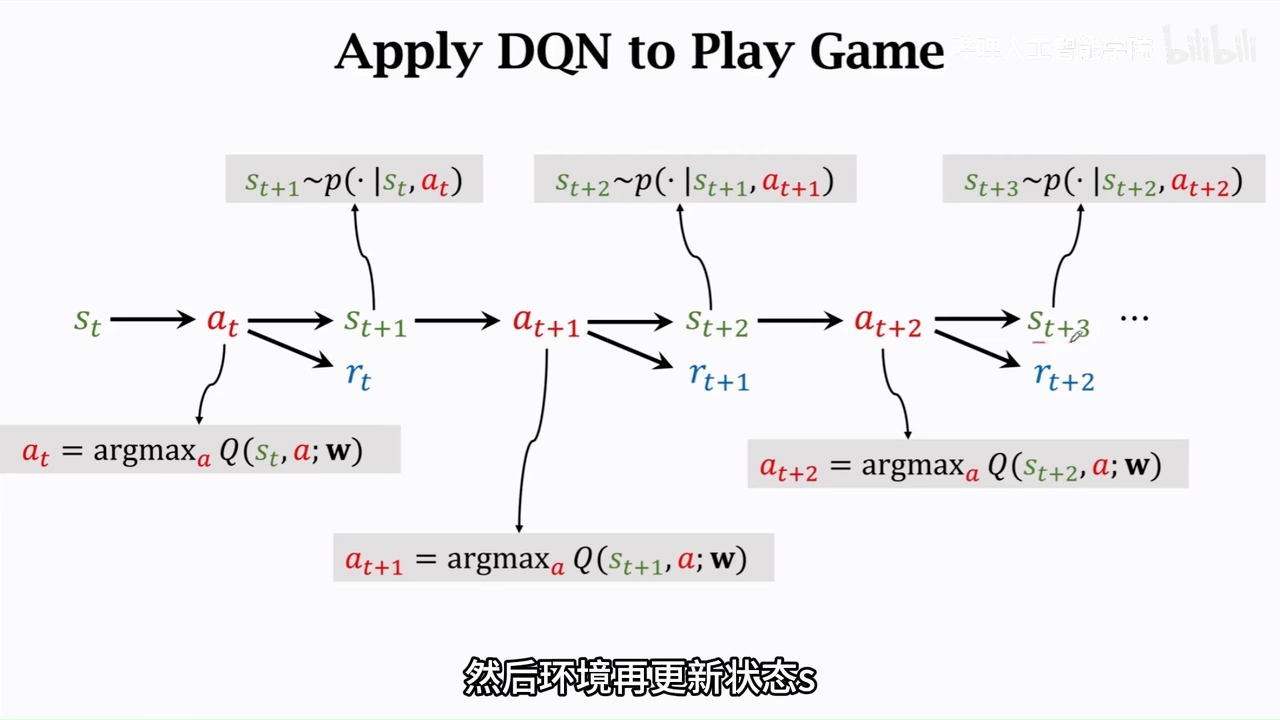
如何训练DQN
图片是一般的模型训练方式,等执行完整过程进行一次更新
这里的alpha是学习率

TD算法我个人的理解
针对一个长任务,在执行任务过程中不断进行结果预测,同时更新模型参数
TD算法部分基于实际结果
这里并不是完整执行之后才更新模型参数

TD target也是估计量,不过部分基于真实值
TD算法的目的是将TD error使劲减小


TD算法的优势
这里的即为,不需要打完完整的游戏既可以更新模型参数
这里的的TD算法计算公式
视频里,不太严谨的证明






价值学习高级技巧
传统方法

经验回放
原始TD算法缺点:
- 浪费了

- 上一帧和下一帧的状态相似,这个对模型是有害的 需要给序列打散,消除相关性
方法
这里在buffer中随机抽取两个s、a来计算TD error
实现了打散时间序列




!

根据TD error判断状态的重要性
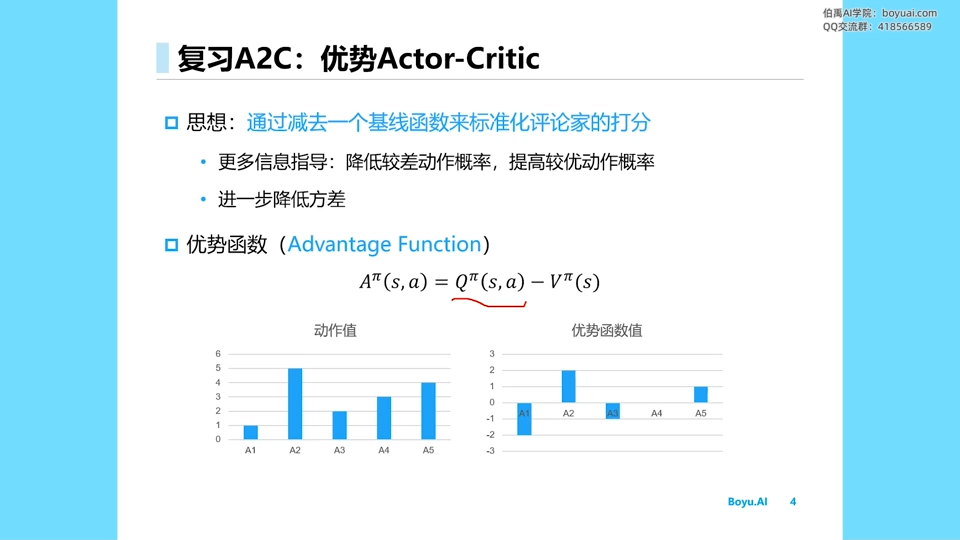
dueling network
优势函数





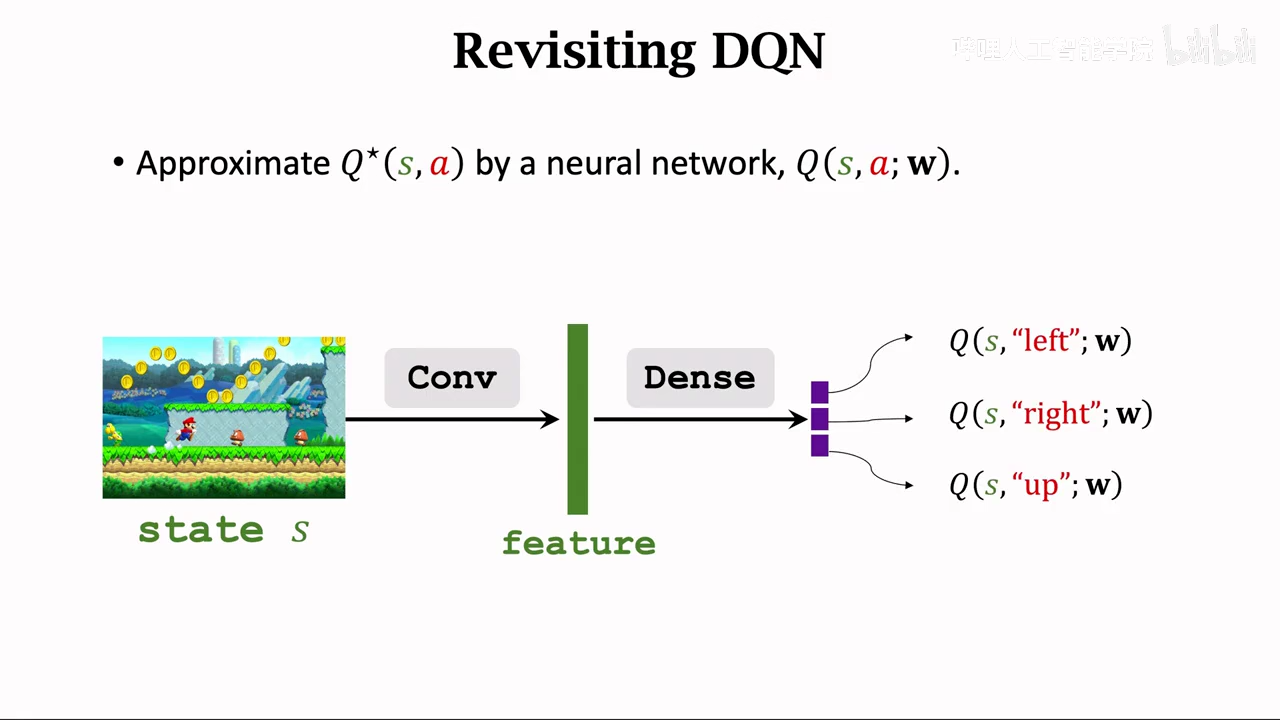
正题
需要训练两个网络
最佳状态函数
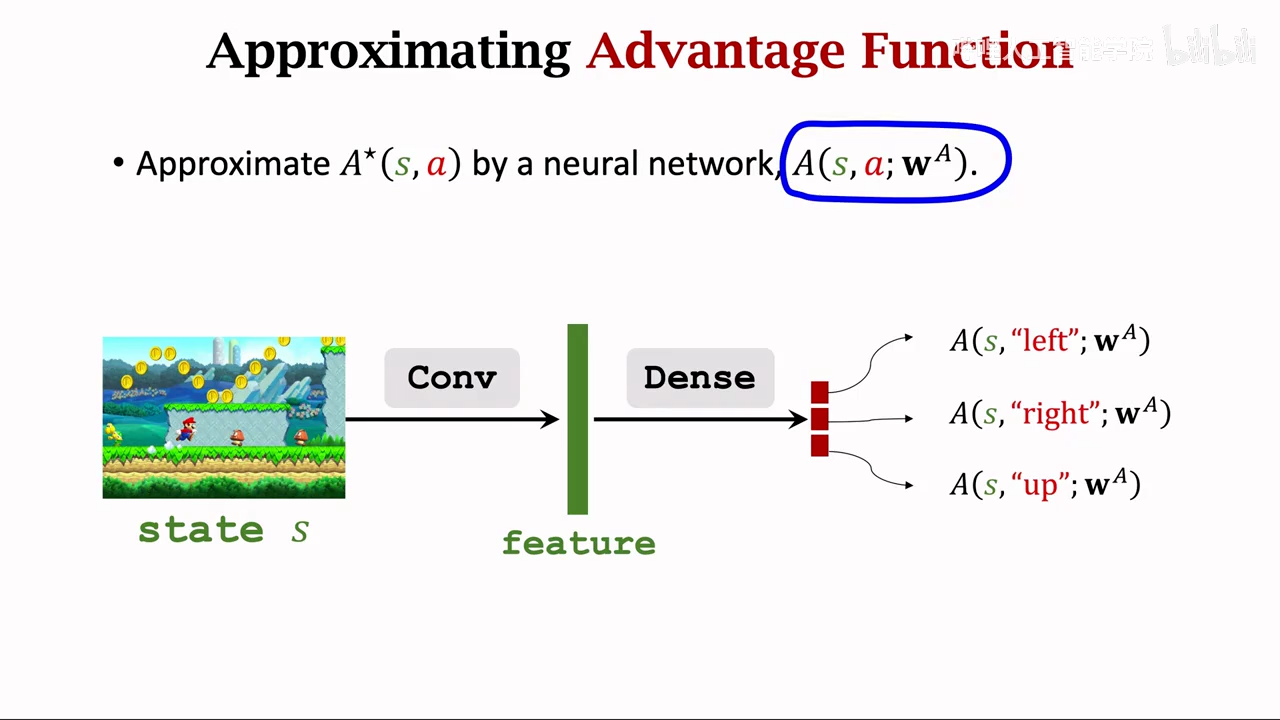
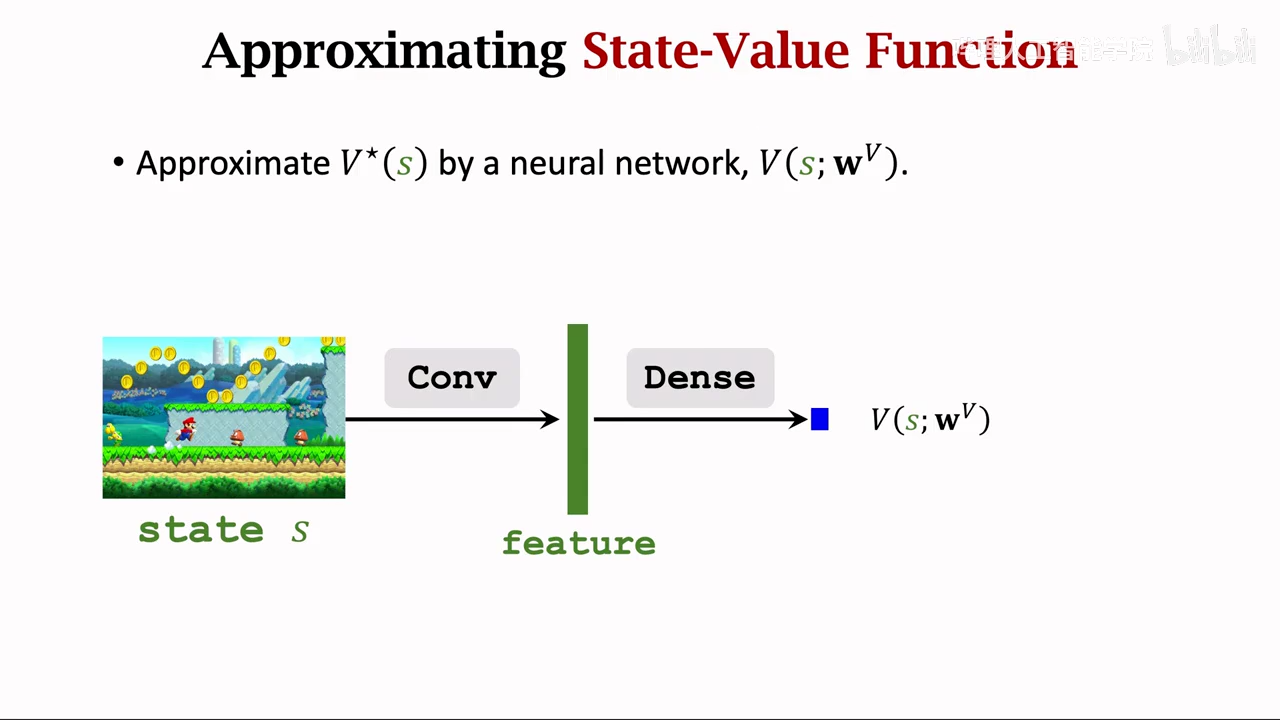

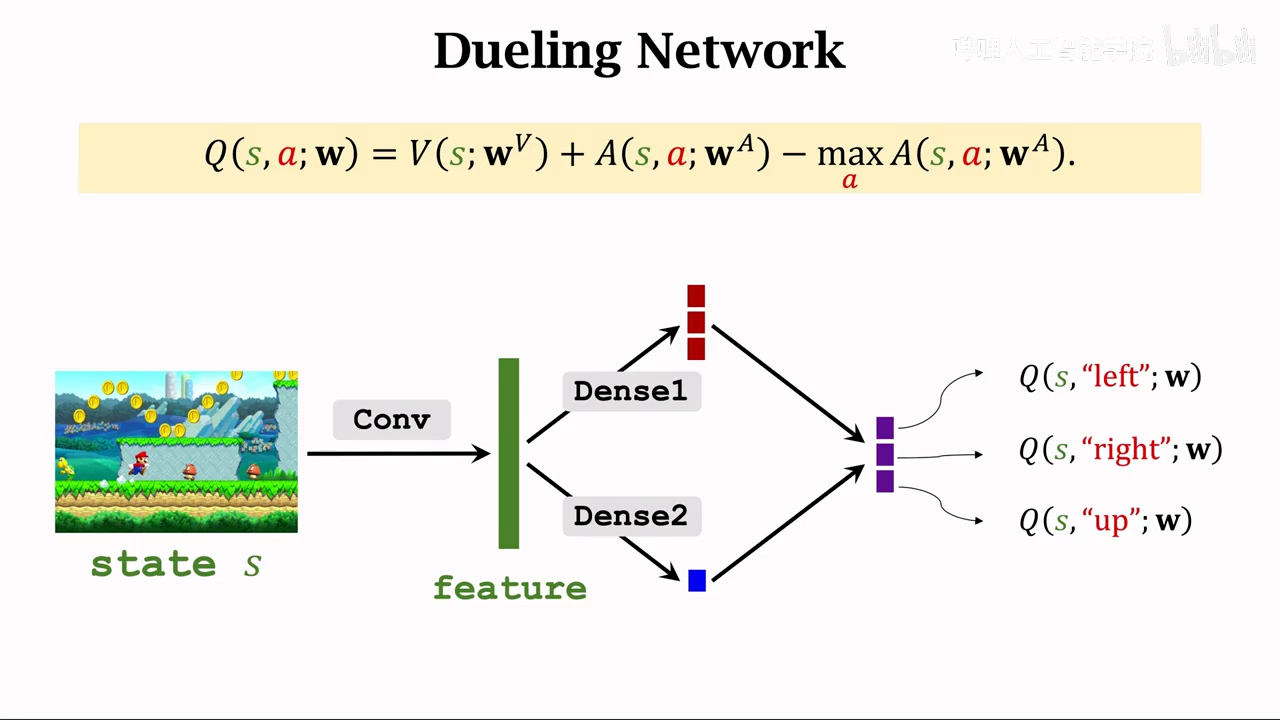
最后将V、A函数进行融合
和DQN一模一样,不影响TD算法
区别只是网络架构区别
最后将V、A进行融合

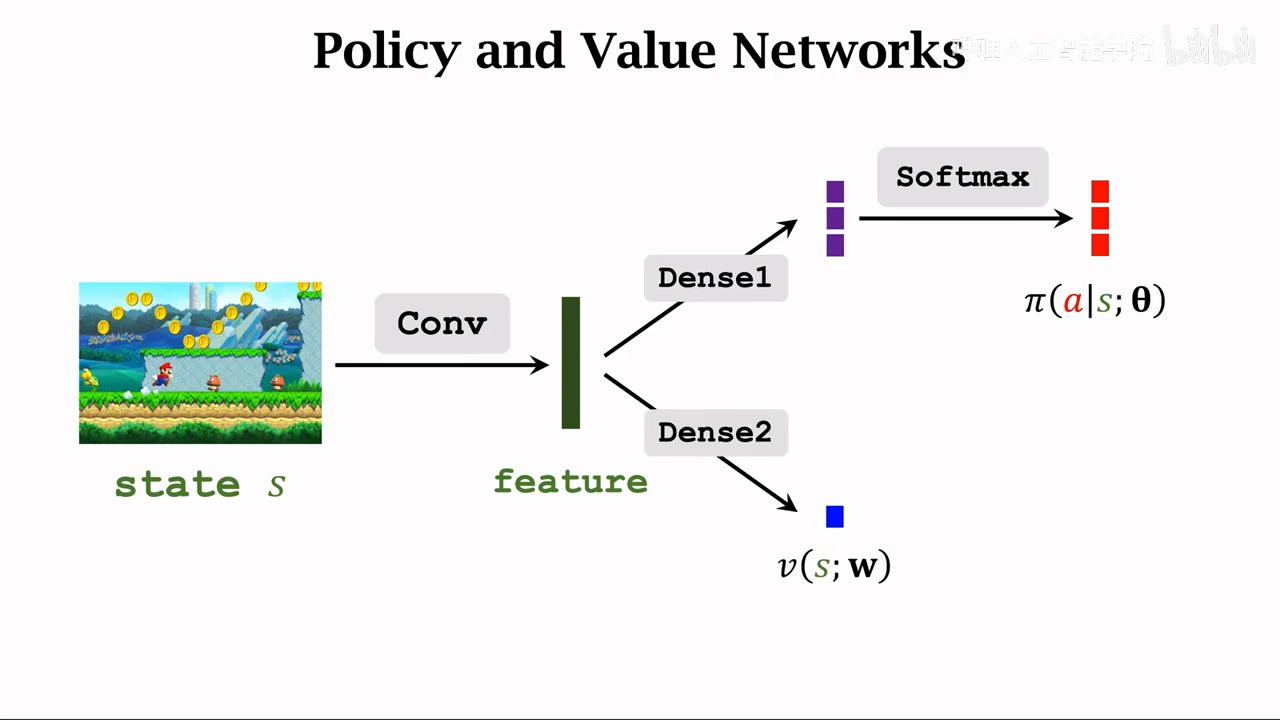
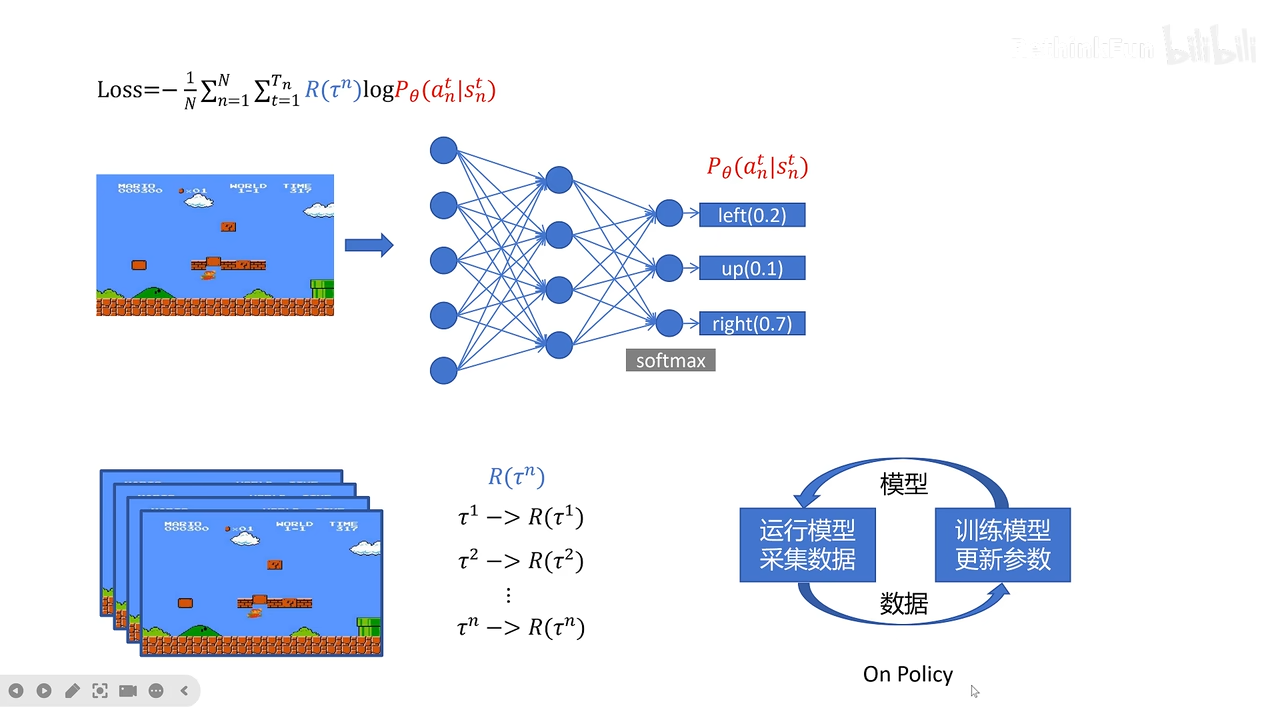
policy-base learning
也就是创建神经网络拟合pi policy策略函数,然后用神经网络近似V pi
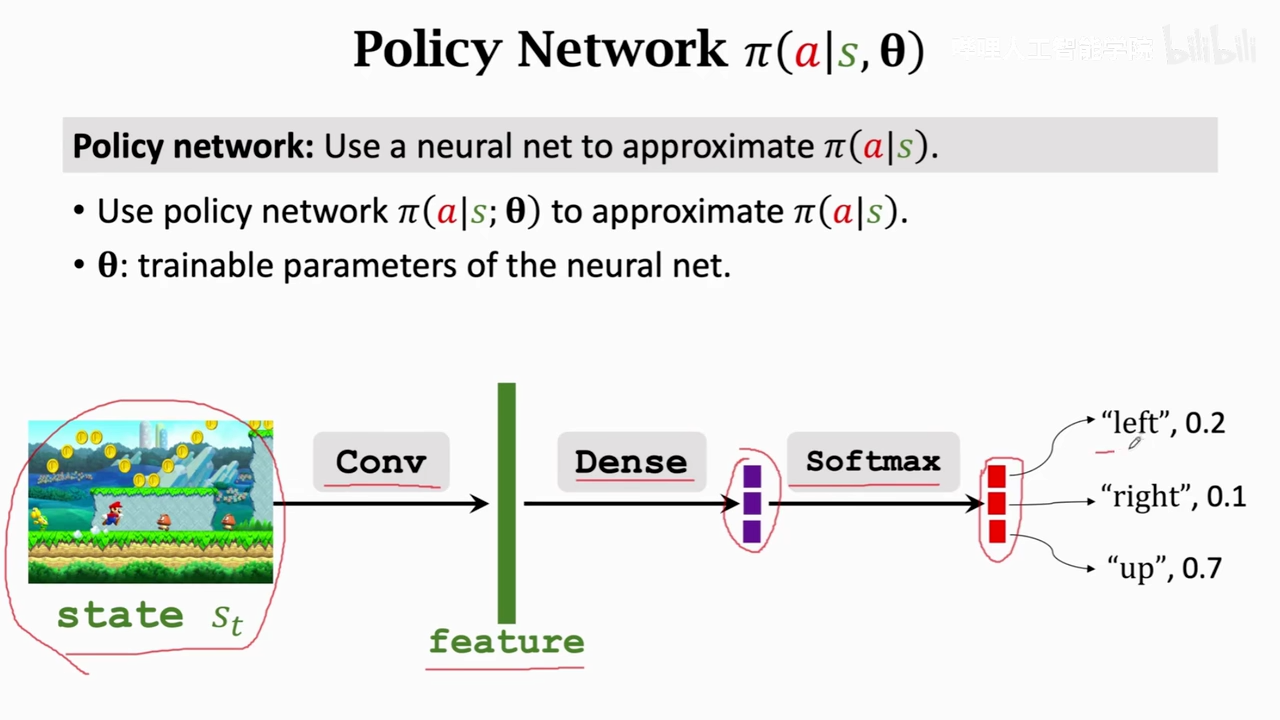

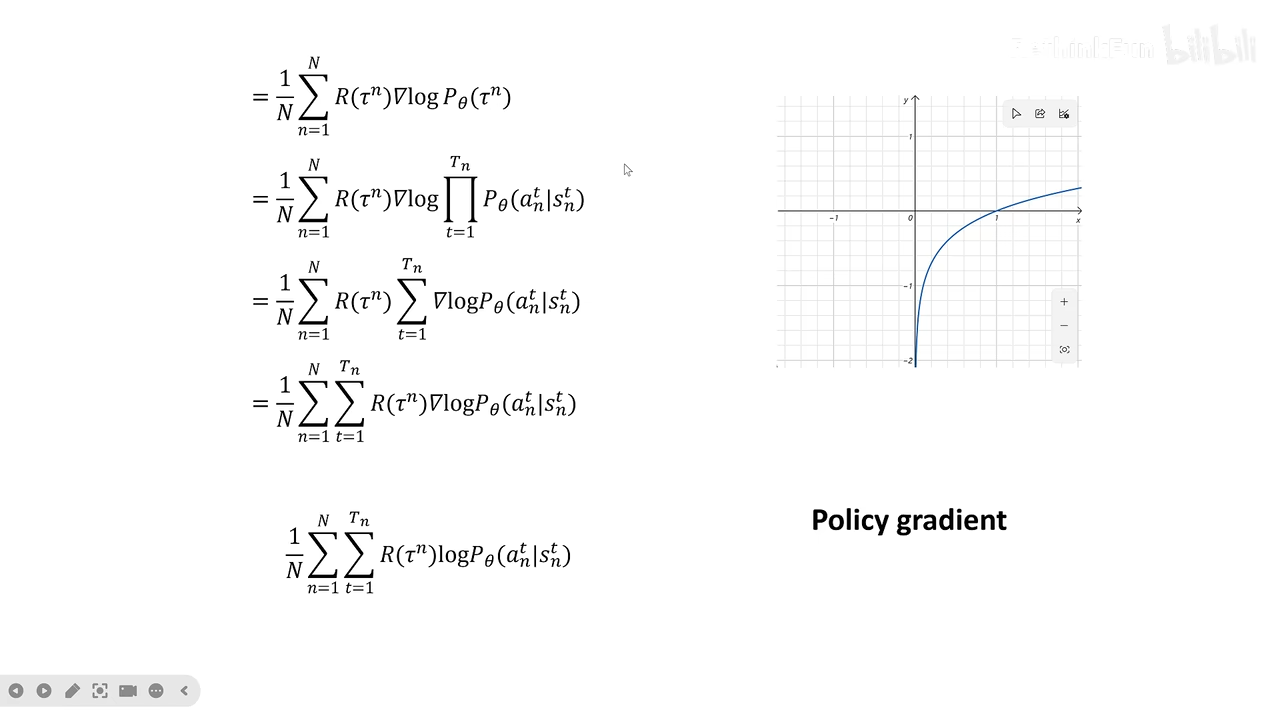
policy gradient
这里有两个求解梯度的方法,一个是针对连续动作,一个是针对离散动作








近似qt方法
- reinforce
- 一个近似pi一个近似qpi。一个actor,一个crtic,两个神经网络
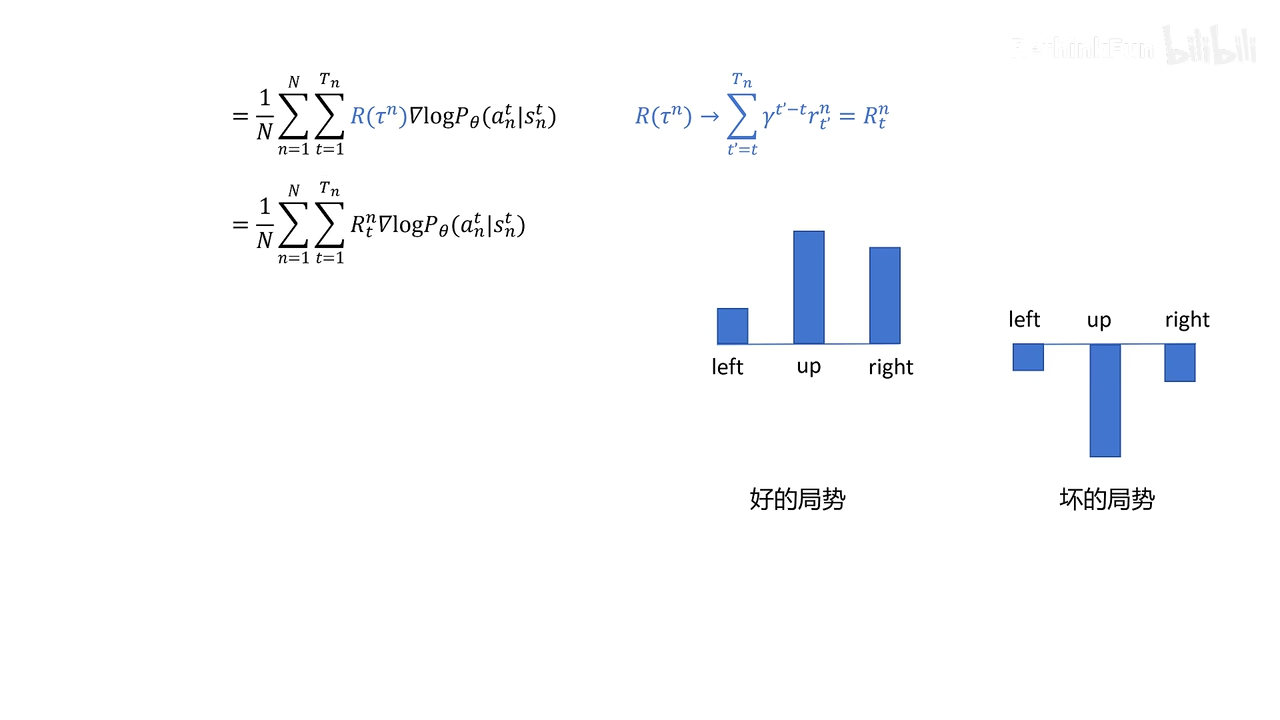
policy gradient with baseline
为什么要添加b,b不会影响期望,但是会影响蒙特卡洛近似
让算法方差降低,收敛更快

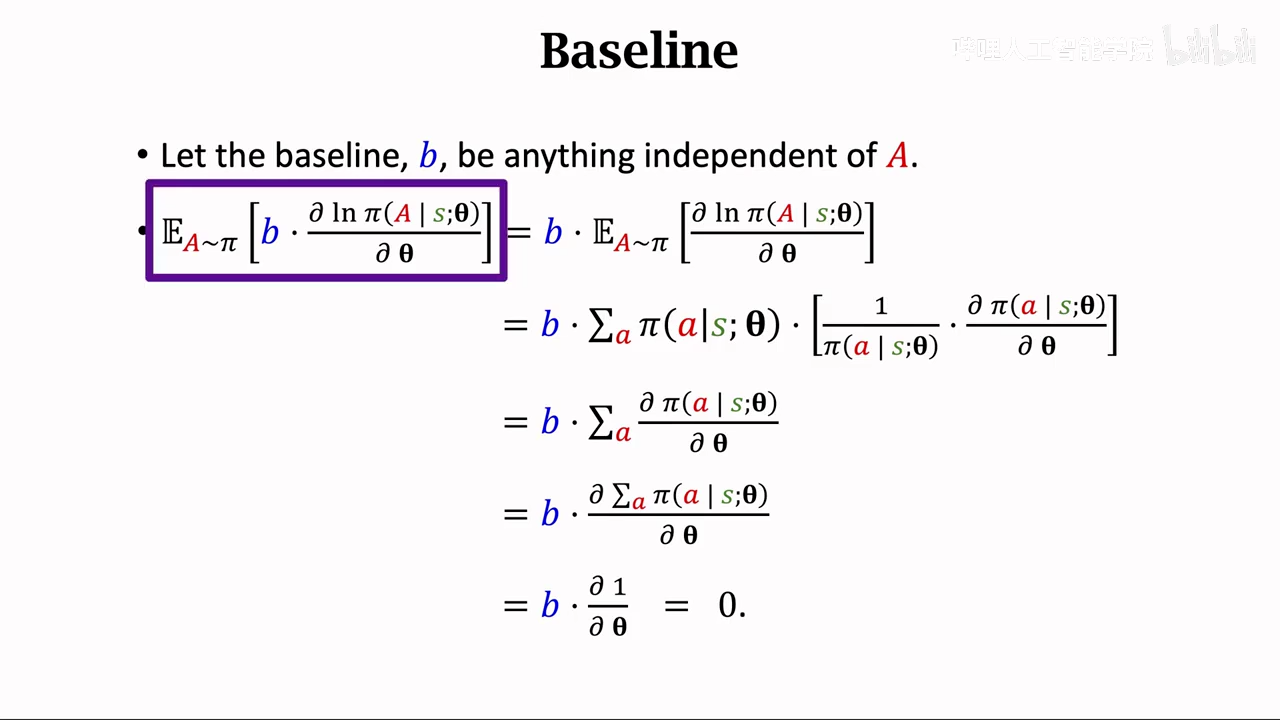




baseline选择


多智能体强化学习
不同队伍之间是竞争关心,而同一个队伍里面的成员是合作关系
利己主义不会刻意伤害或者帮助他人


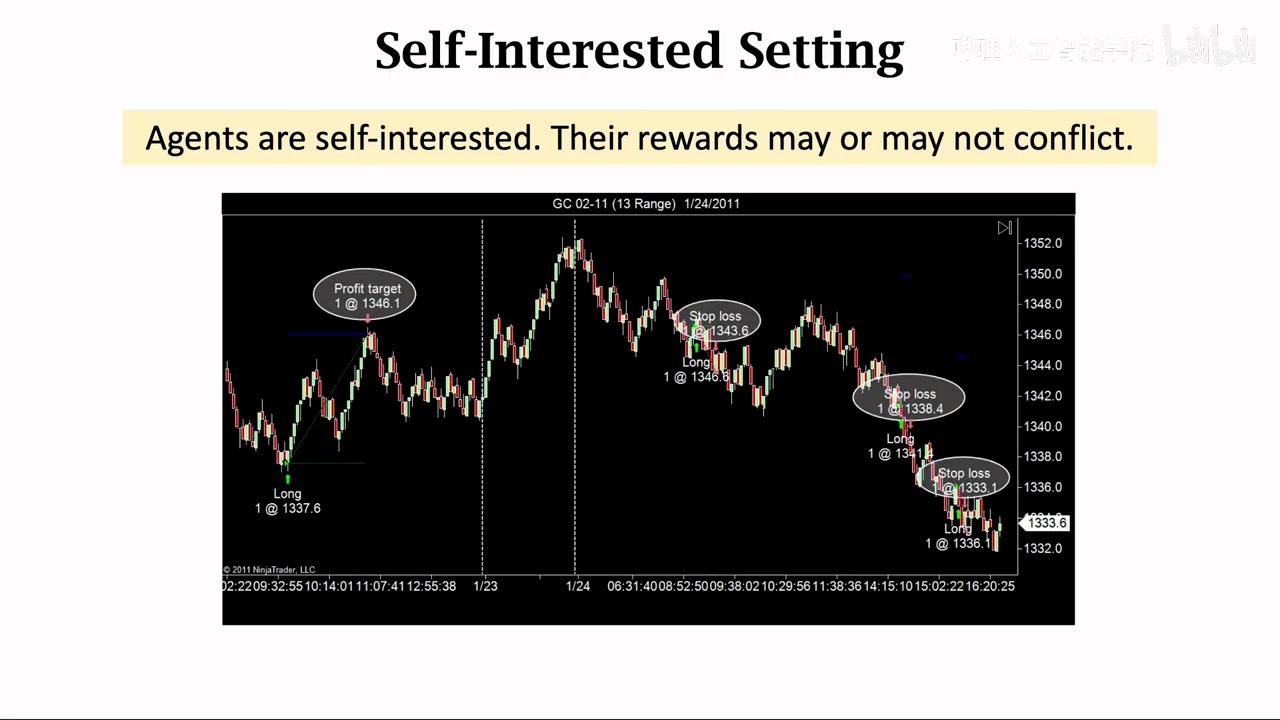



分类


actor-critic methods
重复解释
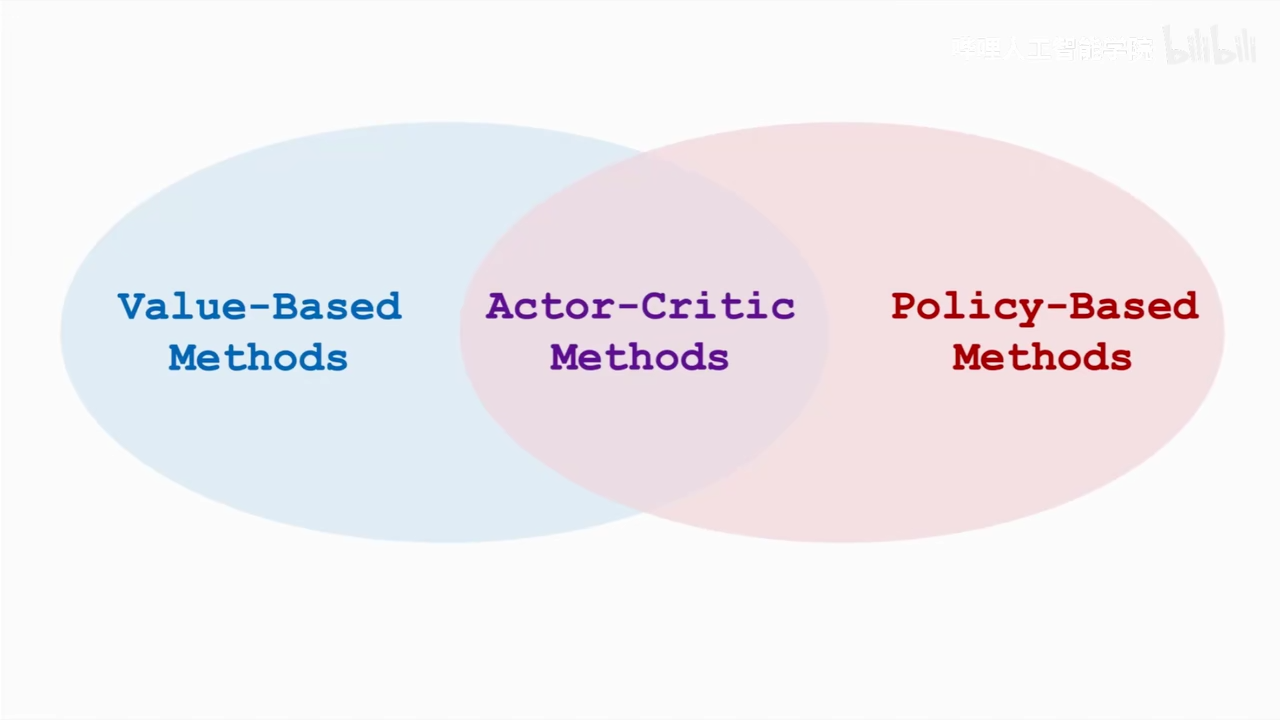

- pi函数是输入状态,根绝policy随机采样动作
- Q pi 是评价当前状态下动作的分数 这里其实就是重复了value base和policy base的神经网络,两个网络都训练 区别就是这里的value network不会控制动作执行,只是对动作打分
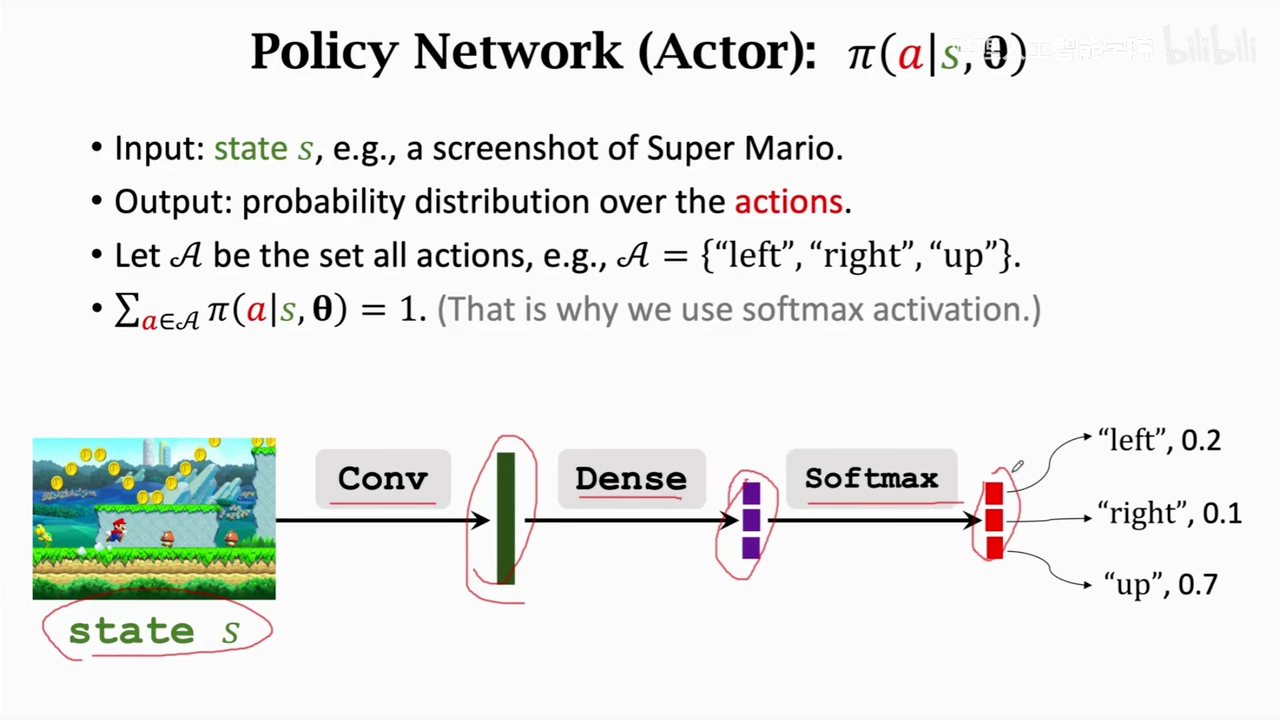
actor
和policy net一致
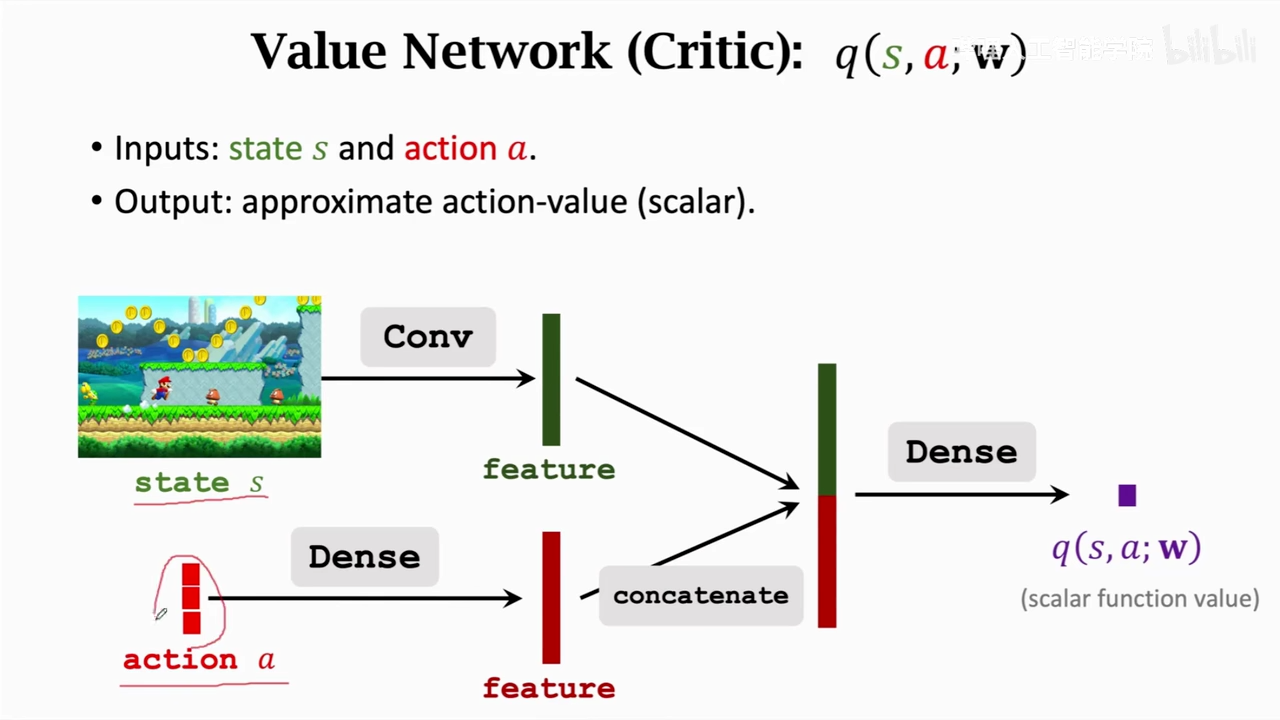
critic
两个输入,状态、动作
actor-critic method
两个网络同时训练
一个网络近似policy net
一个网络近似action-value function
图片中的theta、w是各个网络的参数
两个函数相乘就获取state-value function
运动员表现更好:pi函数根据crtic net(q函数)的打分来进行theta权值的更新
裁判打分更精准:q函数根据reward来更新权重



value net TD
policy policy gradient
alpha是学习率,rt是t到t+1时刻,实际的参数

policy gradient
这里使用的是policy gradient with baseline,注意这里和标准算法不一样,但是效果更好
收敛更快



reinforce with baseline

这里一共进行了三次蒙特卡洛近似






a2c


a2c vs reinforce
a2c中价值网络(v(s;w))作为crtic
而reinforce中只作为baseline:作用降低随机梯度的方差


主要区别就是上图中的部分
a2c部分基于真实值,而reinforce
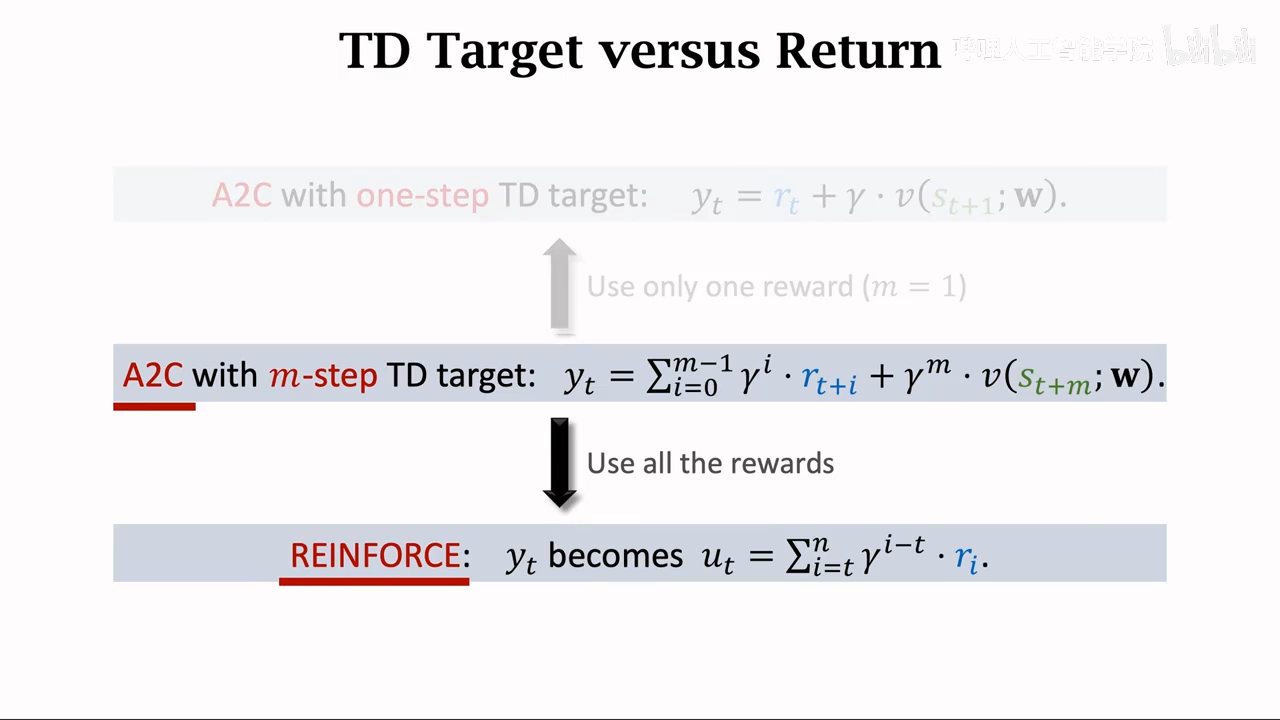
reinfoece是a2c的一种特例
也就是没有使用bootstrapping
bootstrapping也就是在当前状态,估计最后的Ut
可以理解成reinforce执行完全部流程之后才更新奖励

高级模型
a3c
加入了一个异步
并行执行数据采集、actor训练、critic训练
这里有很多worker比较类似多智能体训练,不过实际上a3c还是单智能体,所有的worker都是同一个模型的副本
共享一个全局网络参数


ppo


公式推导

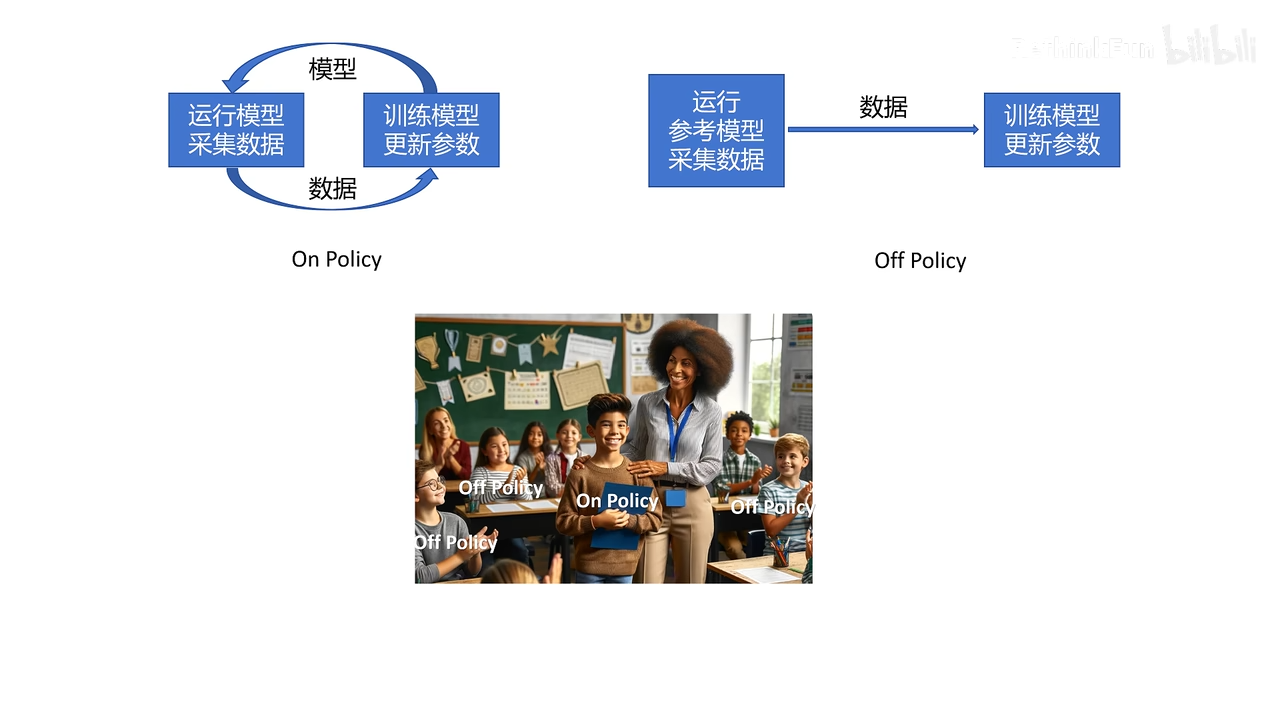
在线学习:采集数据和训练模型的policy是同一个policy
大部分时间都在采集数据
加大当前state的权重。
这里减去了baseline
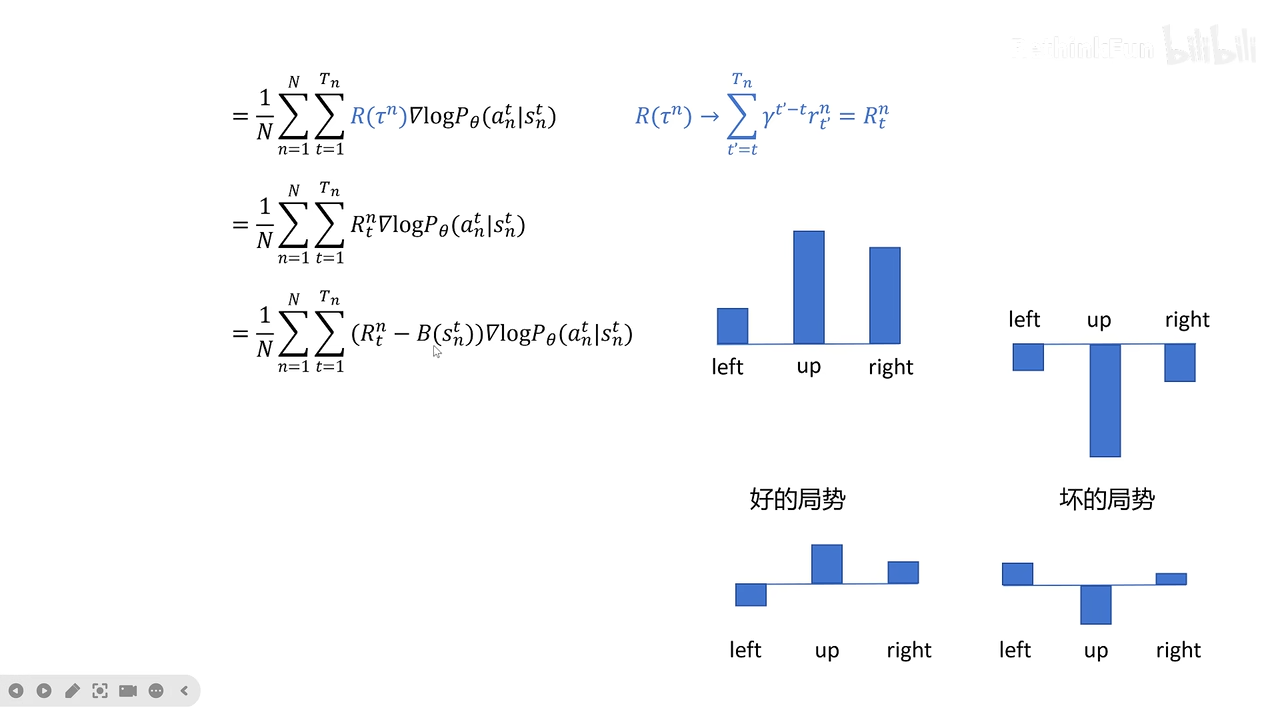
减去baseline其实就是优势函数的意思
采样所有优势函数


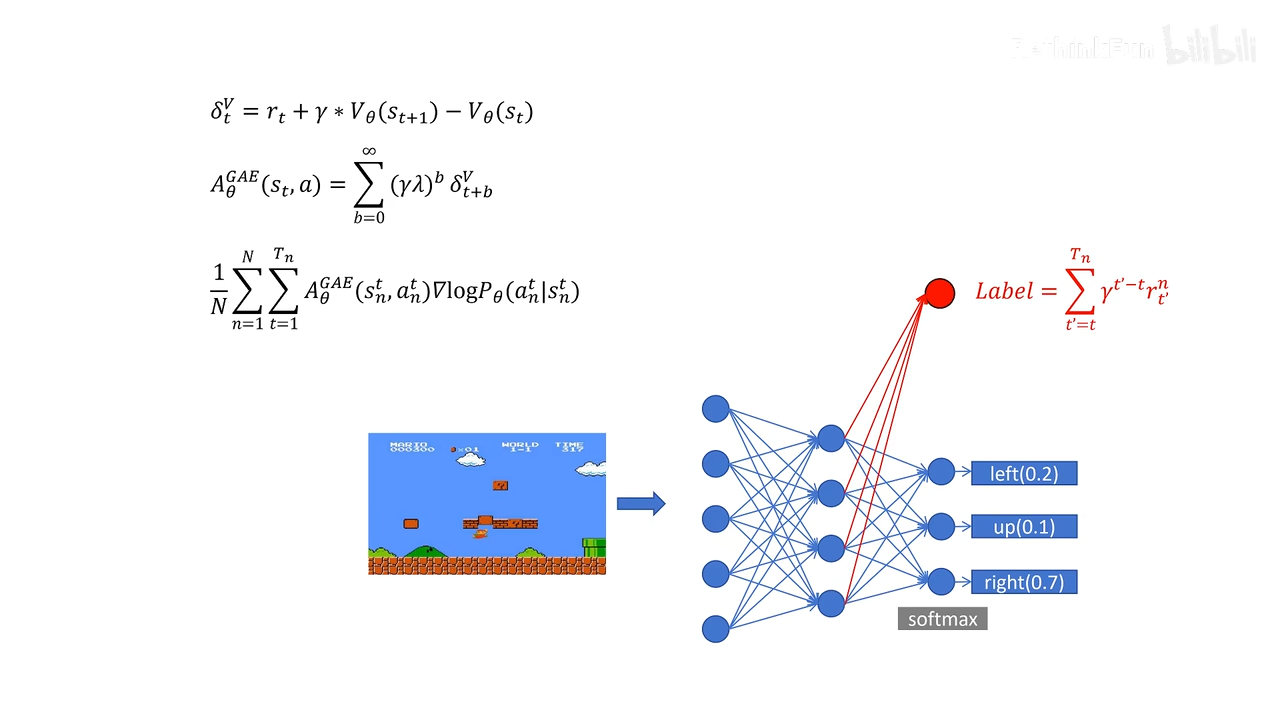
正式学习ppo
这里的off policy 感觉和经验回放很类似
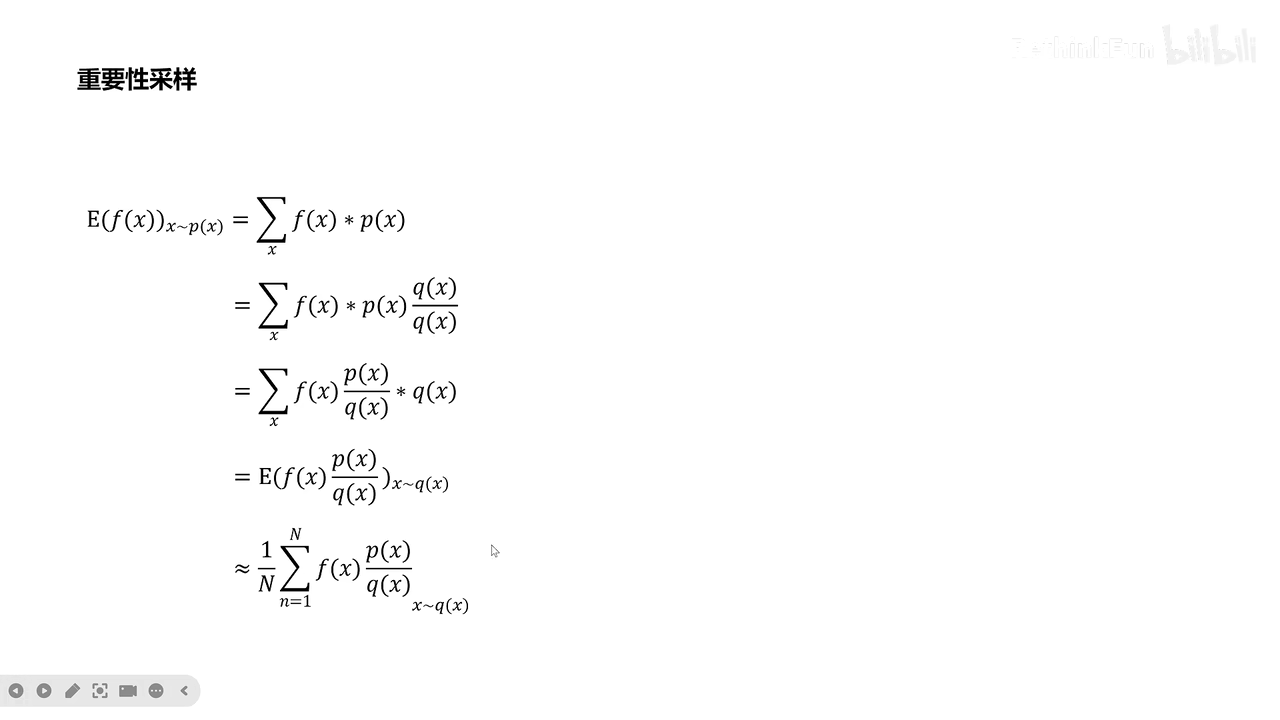

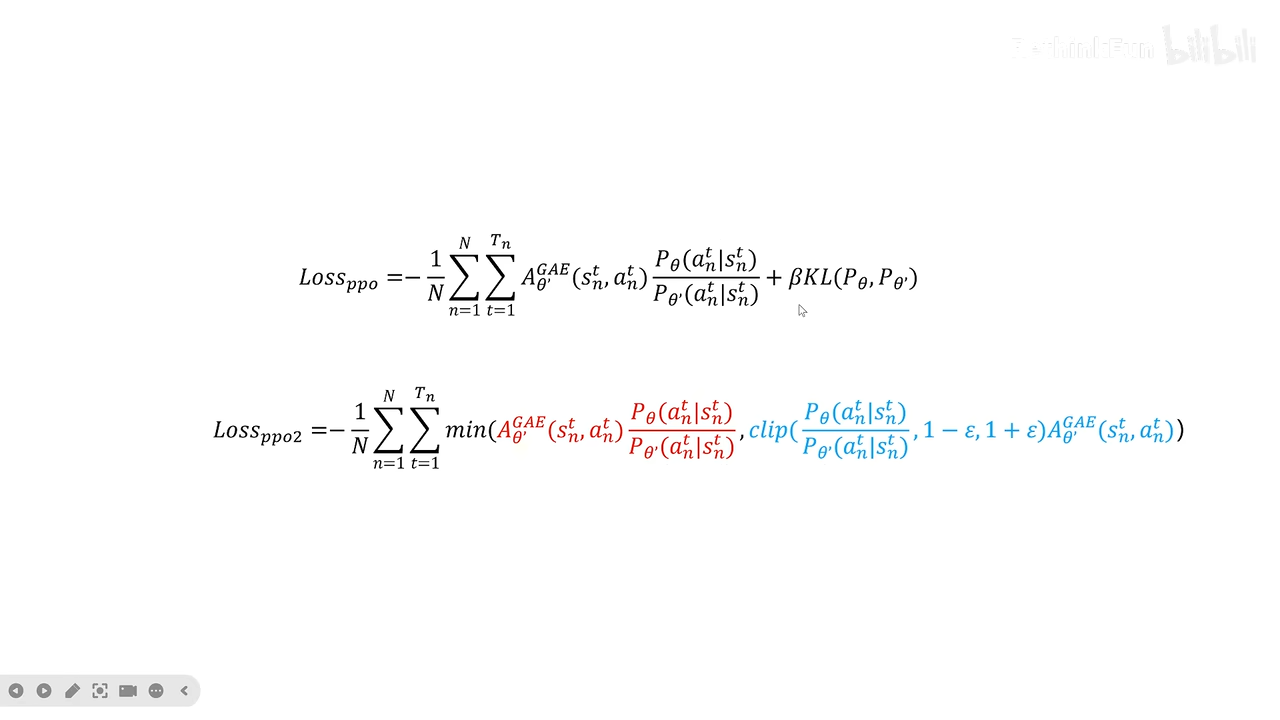
对于和当前agent偏差过大的loss,对于agent训练没有意义,
例如:老师对坏学生的评价不会对好学生有参考意义
这里采用增加kl散度(ppo)、(ppo2)截断函数
alphago

注意alphago不是actor-critic网络,这里的policy和value是分步训练的
这里没有reward
只是单纯的模仿


bahavior cloing 缺陷是如果没有见过某一个状态,网络可能会做出不好的action
因为要使用蒙特卡洛树搜索来优化policy,蒙特卡洛树搜索需要Vpi这个函数
所以需要网络近似Vpi(状态价值函数)
之前几节的网络都是近似Qpi(动作价值函数)
第一步训练的网络基于policy net



monte carlo tree search
alphaGo直接使用树搜索,之前训练的网络只是辅助树搜索
第一步基于pi函数,选择一个概率最大的动作,这里有点像Q* 函数


使用policy代替对手进行操作
进行博弈获取rt

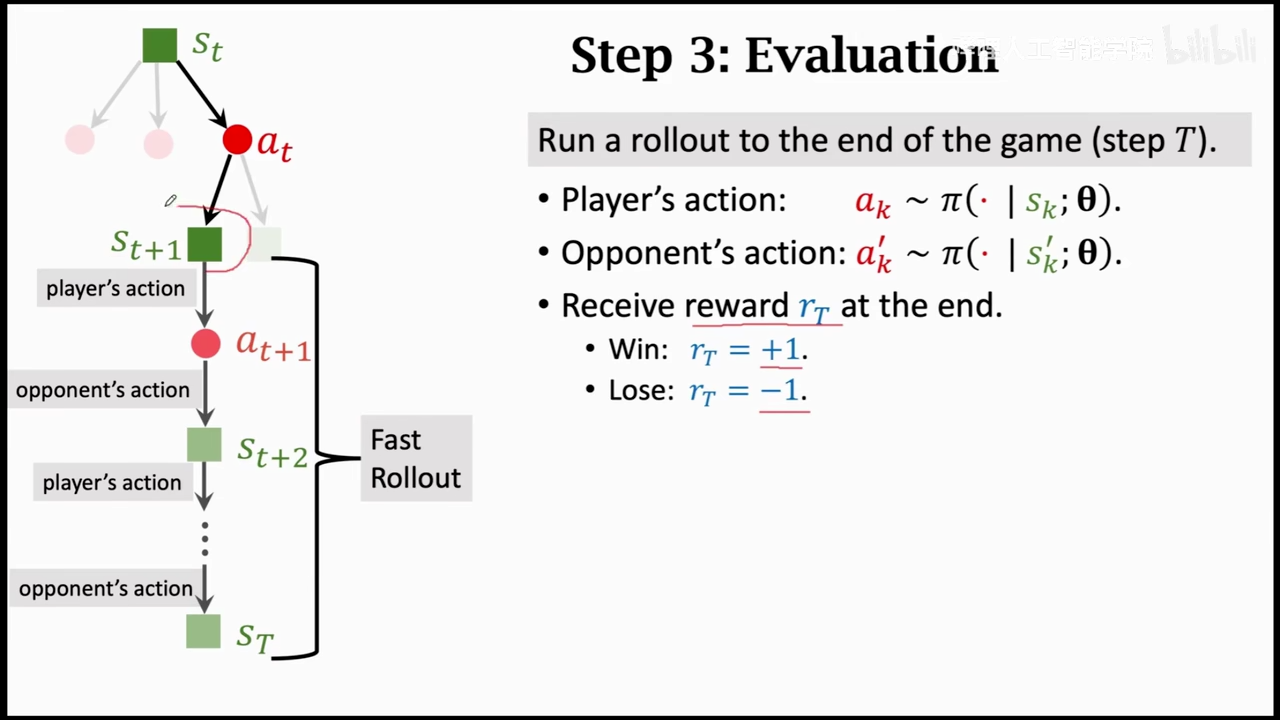
第三步
这里是训练好的value network起作用的地方,这里使用value network来对动作进行打分
然后获取下一个状态的打分,将状态打分和奖励取平均
作为真正的状态评分

将所有的动作评分取平均
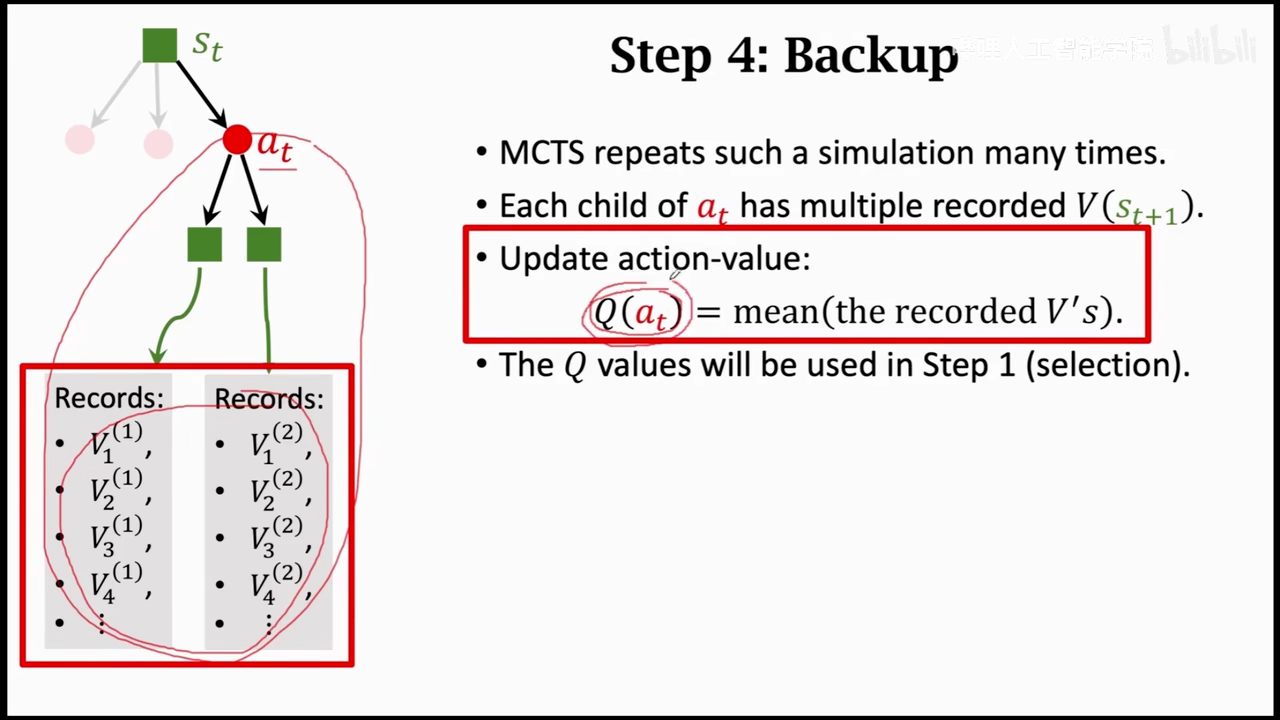
总结


behavior cloning在围棋领域确实没有用,但是在手术机器人、自动驾驶这种不允许出现大量犯错的情况下,可以让模型拟合成一个二流的水平,从而降低实际伤亡



蒙特卡洛树搜索
使用随机样本估算真实值
总结为就是随机采样,然后拟合一个函数,常用在不好算的积分

作用:大量减少计算量,同时可以获取一个较为准确的结果


连续控制
离散动作空间
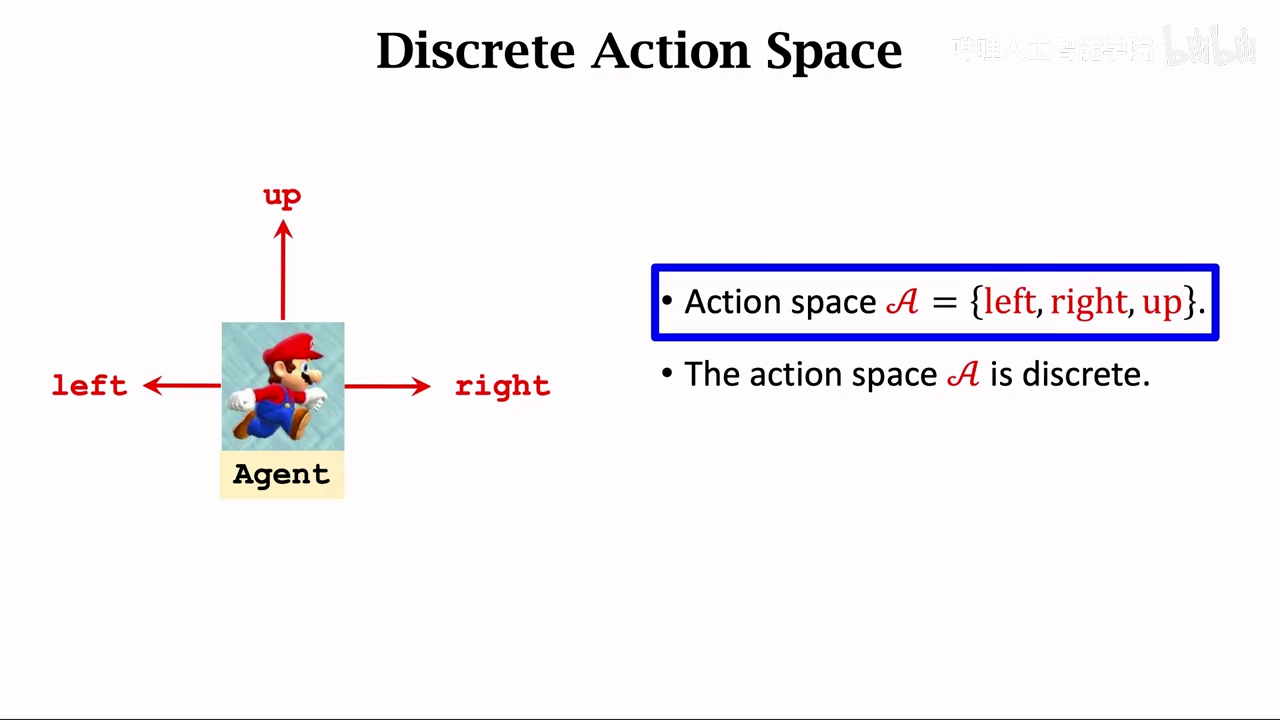

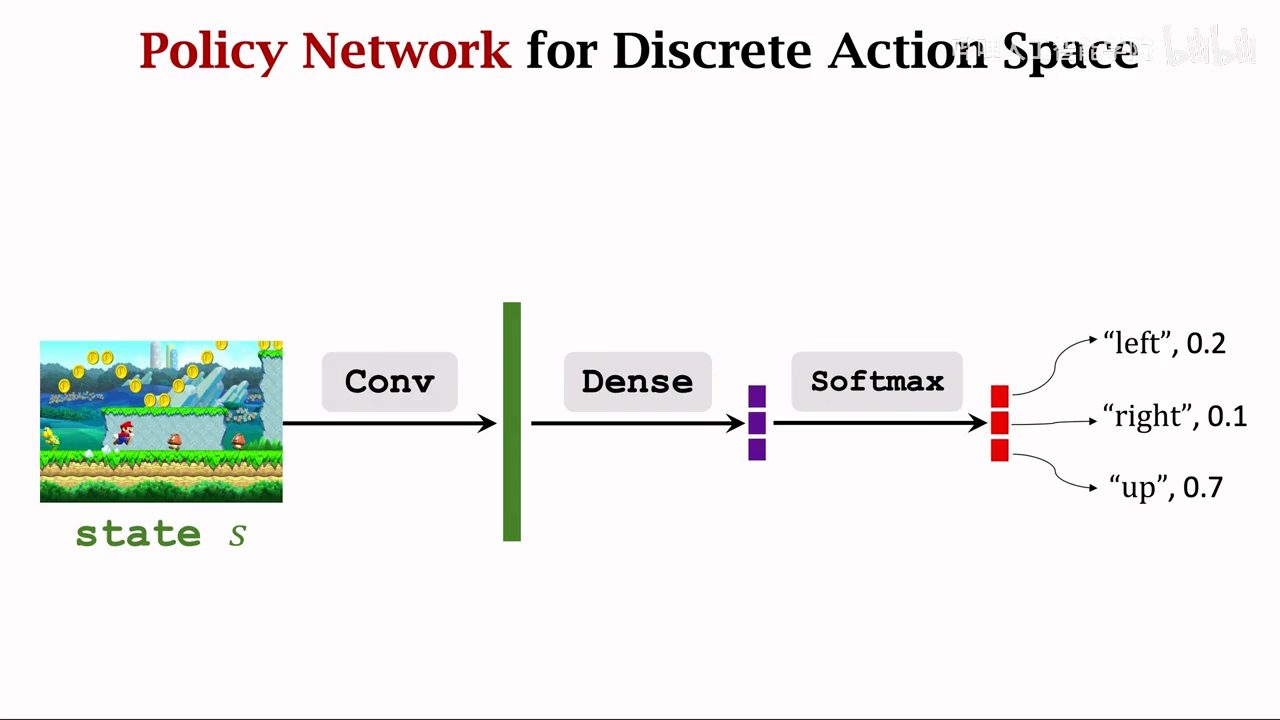
连续动作空间

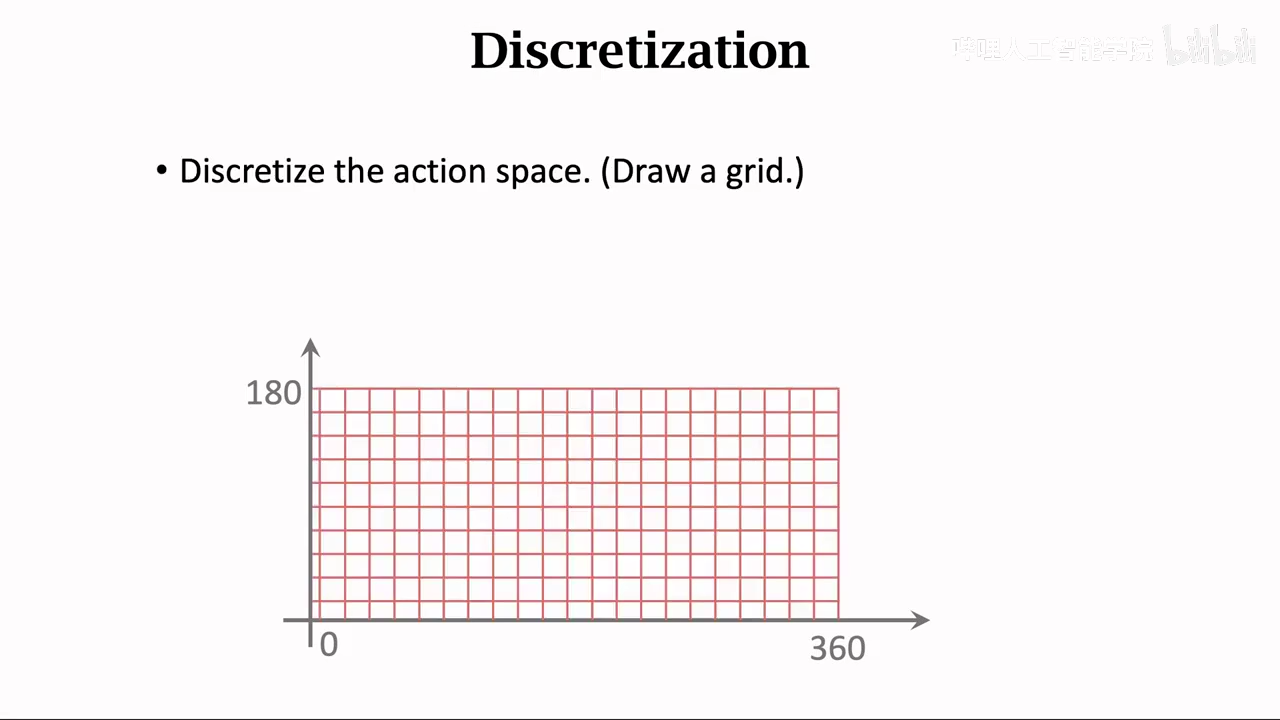
也可以使用dqn或者policy net来控制连续动作,不过需要将连续动作离散化
如果d比较大容易出现动作太多,难以训练

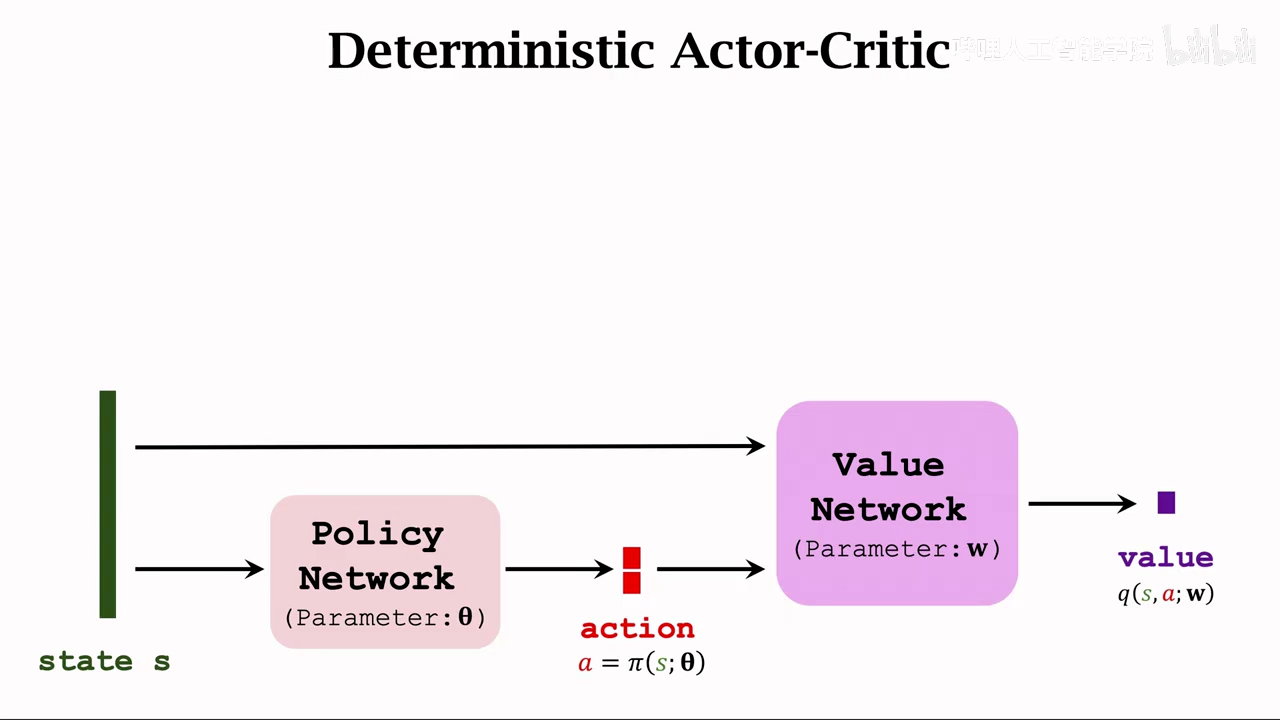
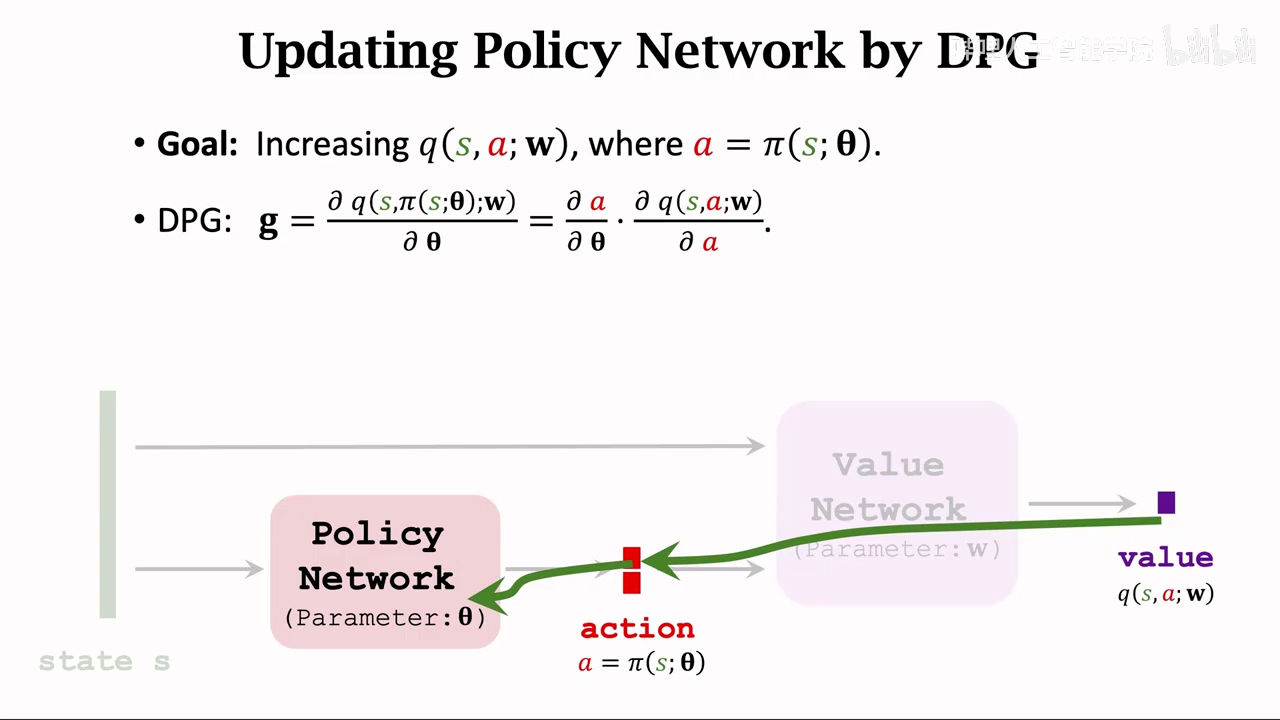
determinister policy gradient(DPG)
先训练价值网络,后训练策略网络


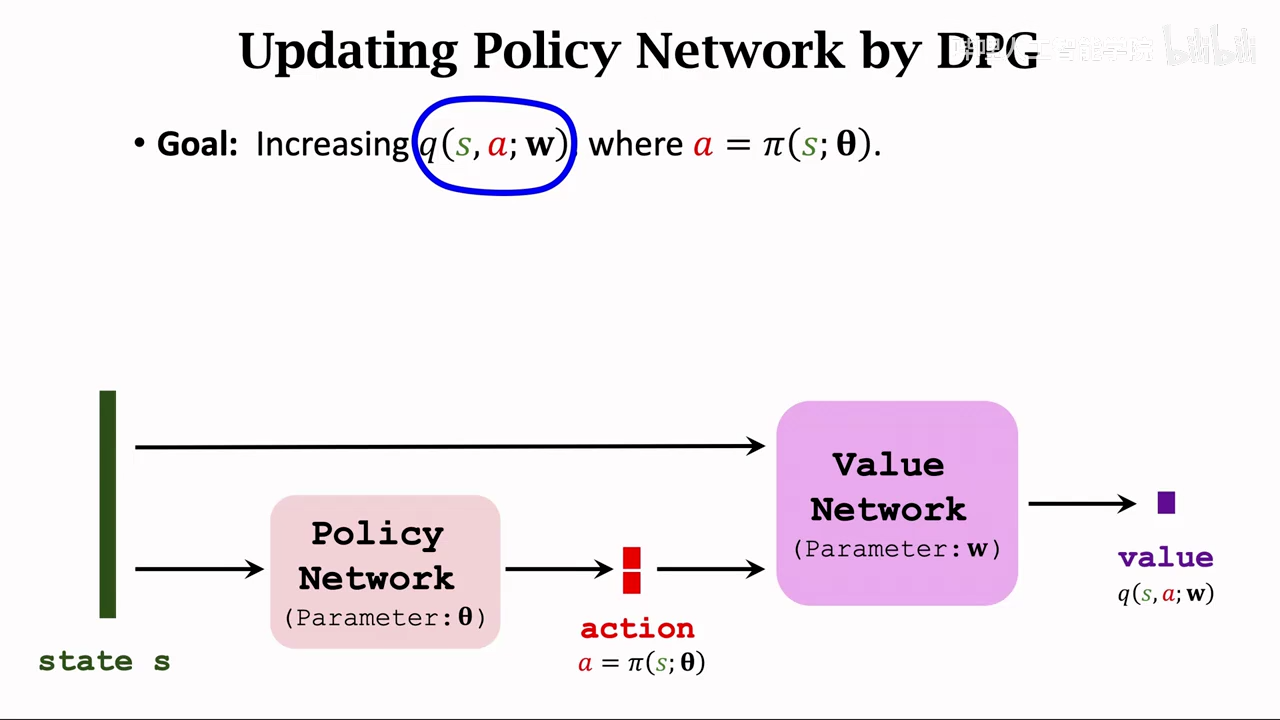
策略网络训练
其实就是从value传导到action

targetnetwork 部分减少bootstrapping的缺陷

随机策略和确定策略
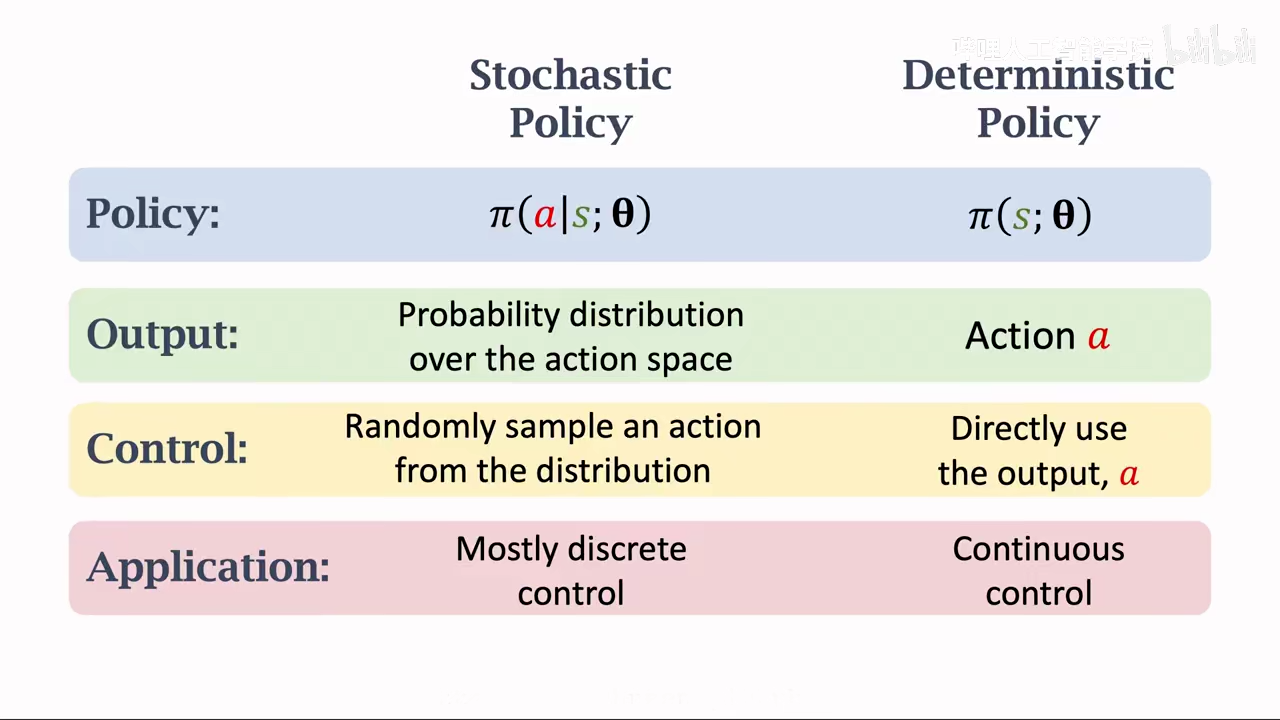
随机策略控制连续动作


自由度等于1
自由度不为1


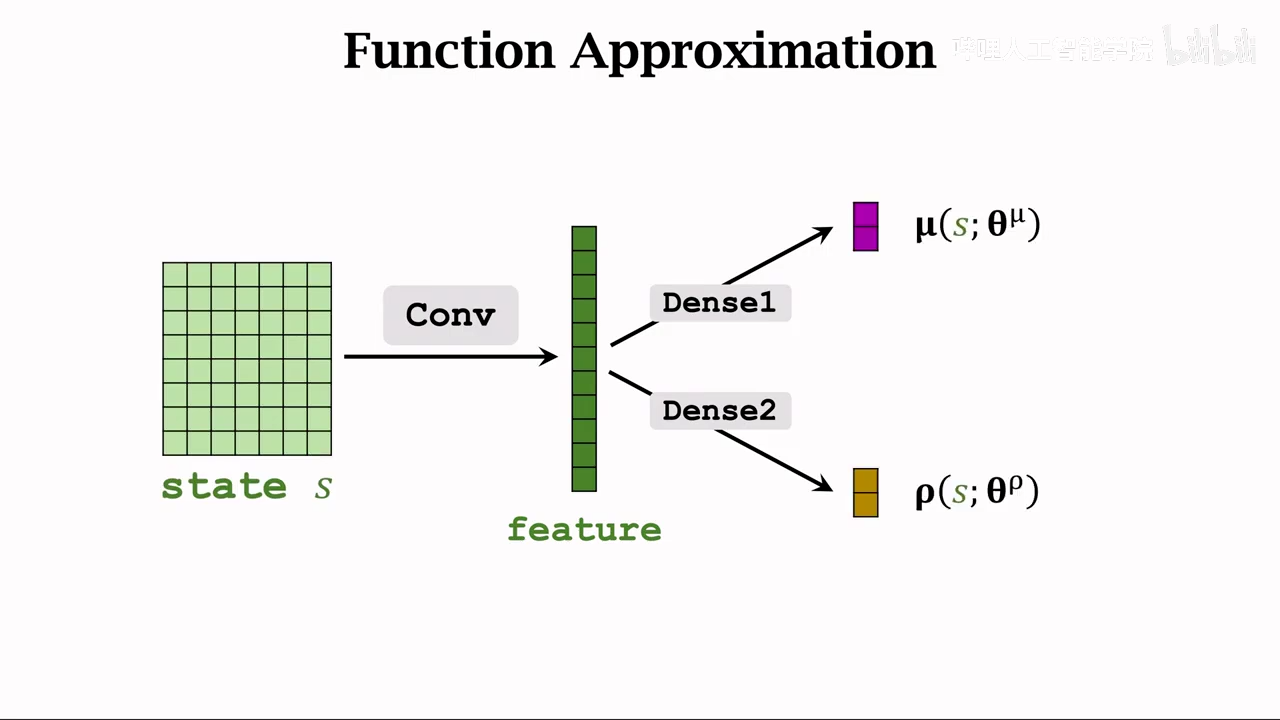
这里又是使用神经网络做近似
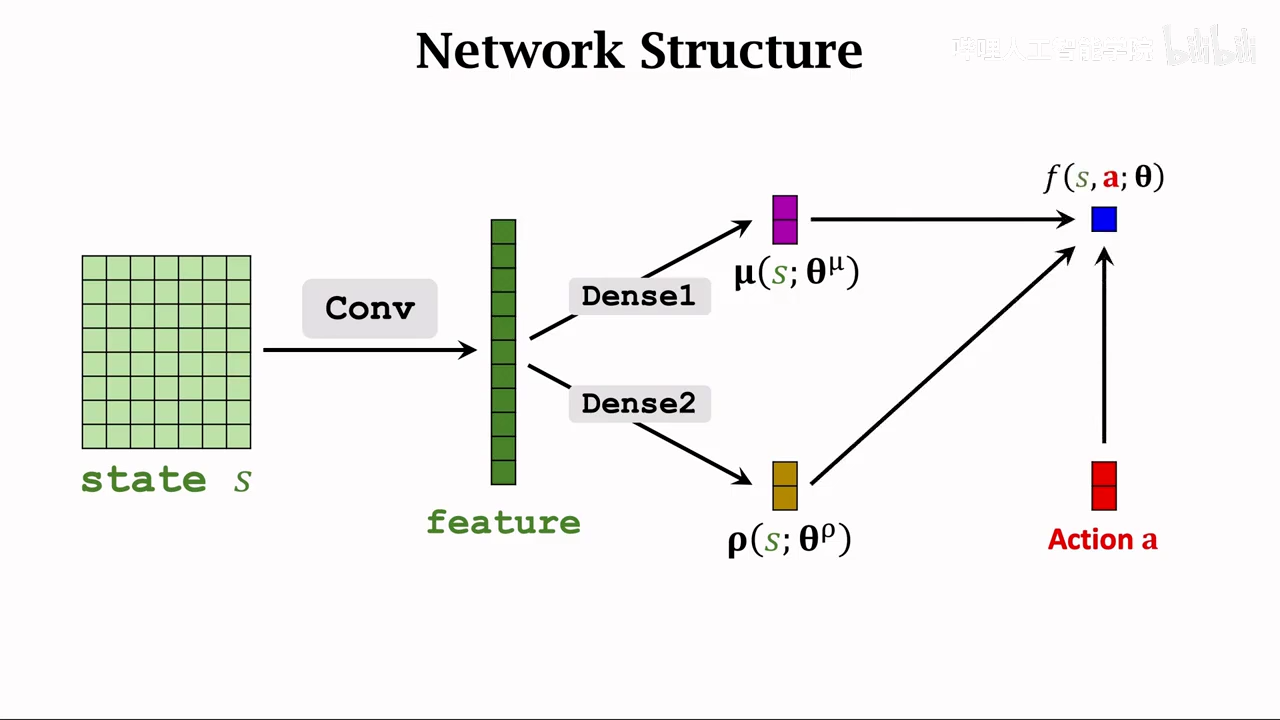
这里采用两个神经网络来近似
共享卷积层
使用不同的全连接层


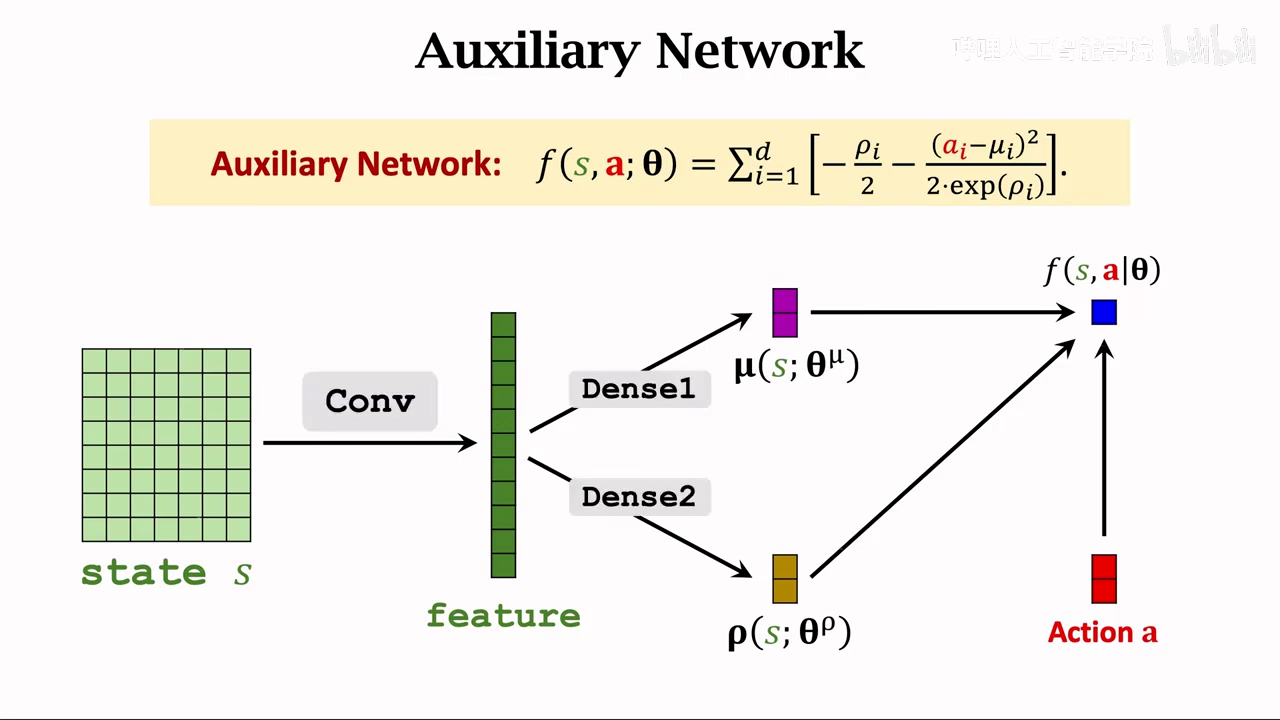
首先使用一个辅助网络辅助计算策略梯度

然后使用策略梯度方法训练策略网络
策略网络计算方法
- reinforce
- actor-critic
第一步 构建辅助网络


反向传导求梯度

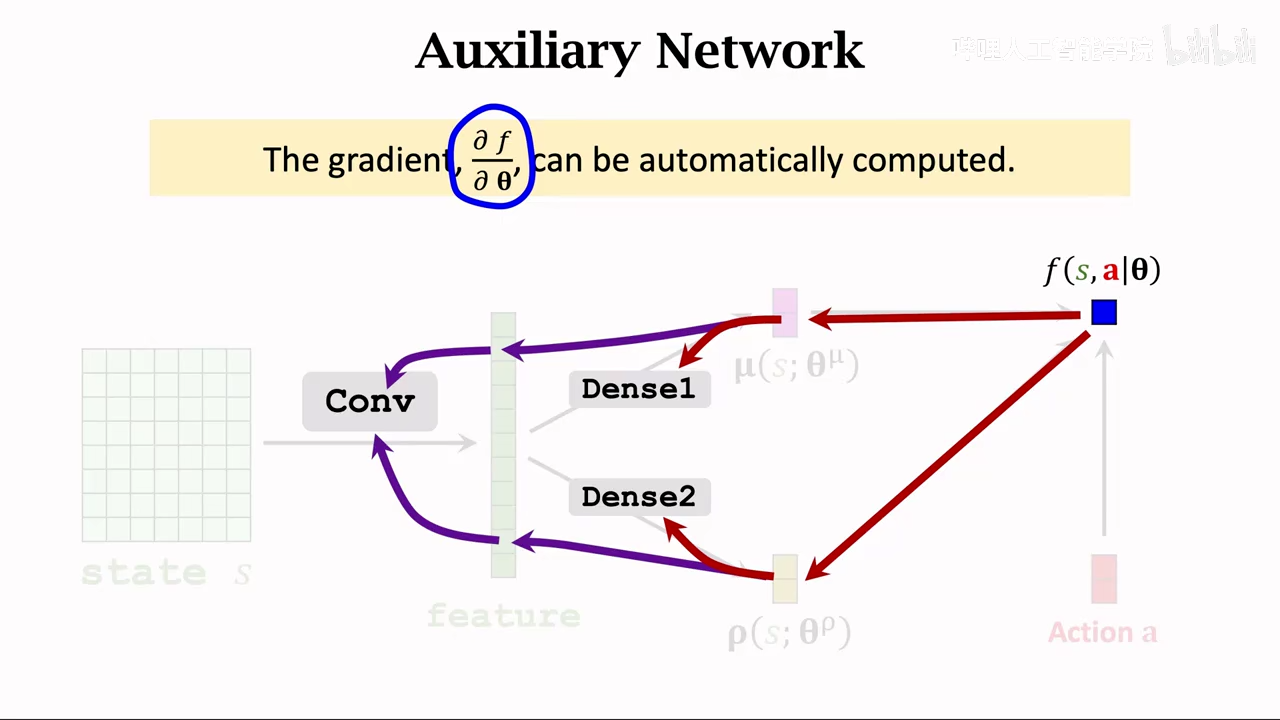

基于策略梯度更新神经网络参数

方法一

方法二

summary
计算策略梯度时,需要使用f关于theta的导数
这也是构造辅助神经网络的原因
检测问题:
- 强化学习的目标是什么? 基于reward寻找最优策略完成任务。而不是贪婪思想,只是思考当下最优。
- DQN 和 Q-learning 的区别是什么? DQN使用了Q-learning的思想
ㅤ | Q-learning | DQN |
状态表示 | Q表(Q-Table):使用表格记录每个状态动作对。 | 神经网络:使用深度神经网络近似 Q 函数 。 |
适用范围 | 仅限离散、小规模的状态空间(如迷宫)。 | 可处理高维、连续的状态空间(如像素图像、机器人传感器)。 |
数据利用 | 逐条学习,实时更新。 | 经验回放(Experience Replay):打破样本间的相关性。 |
更新稳定性 | 容易由于目标值的快速变化而震荡。 | 目标网络(Target Network):通过延迟更新目标网络来稳定训练。 |
- 为什么 PPO 在实际中比 REINFORCE 更稳定? reinforce核心思想是蒙特卡洛近似以及随机采样 ppo核心思想是截断、增加kl散度。限制了新老策略之间的差异不允许过大。 reinforce 和ppo都是on policy策略
因为reinforce采用随机采样、容易出现新老策略区别很大,导致梯度很大,也就是让策略变化更陡峭
因为reinforce每条数据只用一次,而ppo则基于多组数据迭代学习同一组数据,对数据的重复利用更好。所以ppo更稳定
- A3C 的优势是什么? A3C(Asynchronous Advantage Actor-Critic) 优势一、异步并行 可以同时运行多个workers,每个worker可以进行独立采样,更新网络参数 这样就导致模型的训练速度变快 优势二、实现数据缓存 每个worker也有保存数据的作用,不需要经验回放池、节省内存。