type
Post
status
Published
date
Dec 15, 2025 05:40
slug
summary
tags
gr00t
humanoid
robotics
flow-matching
category
工具
icon
password
文本
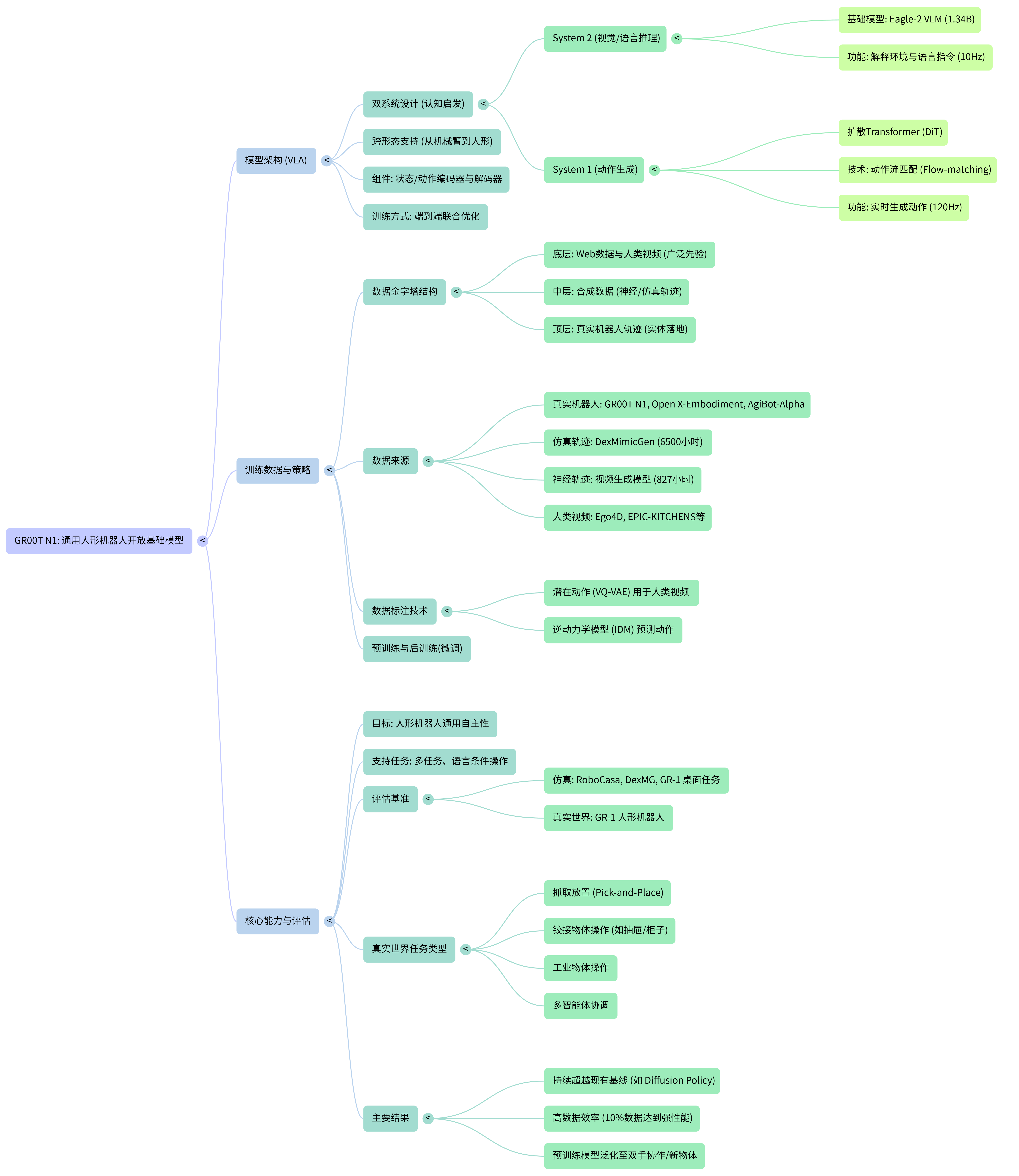
0. 元数据 (Meta Data)
- Title: GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
- Authors: NVIDIA (Scott Reed, Ruijie Zheng, Guanzhi Wang, et al.)
- Venue: arXiv 2025 (Technical Report)
- Tags: #Humanoid #VLA #FoundationModel #DataPyramid #Sim2Real #FlowMatching
- One-Liner: NVIDIA 推出的人形机器人通用基座模型,采用类人脑的“System 1 (运动小脑) + System 2 (推理大脑)”双系统架构,并通过构建包含人类视频、神经渲染视频和真机数据的“数据金字塔”策略,解决了人形机器人数据稀缺与高频控制的矛盾,,。
1. 核心痛点与动机 (The "Why")
Context: 在这篇论文出来之前,人形机器人领域存在什么核心难题?
- 痛点 1: “数据孤岛”与极度稀缺 (Data Islands & Scarcity)
- 现状: 相比于互联网上的文本和图像数据,人形机器人的高质量物理交互数据极其昂贵且稀缺。现有的数据集往往是针对特定硬件的,彼此之间无法互通,形成了一个个孤立的“数据群岛”,。
- 比喻: 就像想教一个孩子学外语(通用智能),但手头只有几页方言字典(特定机器人数据),这点数据量根本喂不饱大模型这个“大胃王”。
- 痛点 2: “大脑”与“小脑”的速率失配 (Reasoning vs. Control Frequency)
- 现状: 通用机器人既需要极强的语义理解能力(如理解“把那个像苹果的东西拿给我”),又需要极高频率的电机控制(如保持双足平衡)。传统的 VLA 模型如果全部用大语言模型(LLM)来做,推理速度太慢(如 <10Hz),无法满足机器人高频控制(>100Hz)的需求。
- 比喻/洞见: 这就是典型的**“大脑思考人生(System 2)”与“小脑维持平衡(System 1)”的矛盾**。如果让大脑去管每一块肌肉的实时收缩,不仅累死,反应还跟不上。
2. 核心创新点 (The "How")
Context: 论文是如何一步步解决上述痛点的?
2.1 输入输出流 (I/O Stream)
- Input (感知端):
- 视觉: RGB 图像观测(Image Observation)。
- 语言: 文本指令(Language Instruction)。
- 状态: 机器人本体感知状态(Proprioceptive State),包括关节位置、速度等,通过特定实施例的编码器(MLP)投影到共享嵌入空间,。
- Output (动作端):
- 形式: 去噪后的动作块(Action Chunk),通常包含未来 16 步的动作向量(如关节位置/旋转),。
- 频率: 高频闭环控制(120Hz),远高于视觉推理模块的频率(10Hz)。
2.2 核心模块与选择原因 (Module & Selection)
- System 2: 推理模块 (VLM Backbone - NVIDIA Eagle-2)
- 选择理由: 负责“慢思考”。利用 Eagle-2 (基于 SigLIP-2 和 SmolLM2) 强大的视觉语言对齐能力,处理环境感知和任务理解,输出 Vision-Language Token,。这相当于给机器人装了一个“见过世面”的大脑,能理解通用语义。
- System 1: 动作模块 (Action Module - Diffusion Transformer)
- 选择理由: 负责“快反应”。采用基于 Flow-matching(流匹配)的 Diffusion Transformer (DiT)。相比于传统的 MSE 回归,扩散模型能更好地拟合多模态分布(Multimodal Distribution),避免产生“平均化”的无效动作;相比于标准扩散模型,Flow-matching 推理更高效,。
- 架构亮点: 这是一个双系统(Dual-system)紧密耦合的设计。System 1 通过 Cross-Attention 接收 System 2 的高层指令,但拥有独立的 DiT 网络来高频生成动作,完美解决了“懂得多”和“动得快”的矛盾,。
3. 数据策略与创新 (Data Strategy)
Data is the new code. NVIDIA 展示了暴力美学之外的数据炼金术。
- 数据金字塔结构 (The Data Pyramid):
- 塔基 (Base): 海量 Web 数据和人类视频 (Human Videos)。量最大,但含噪且无动作标签。
- 塔身 (Middle): 合成数据 (Synthetic Data)。包括仿真数据和神经渲染轨迹 (Neural Trajectories)。
- 塔尖 (Top): 真机数据 (Real-World Data)。量最少,质量最高,用于对齐物理世界。
- 创新点 (Innovation):
- 神经轨迹 (Neural Trajectories - Dreaming Data): 利用视频生成模型(Video Generation Models)将有限的真机数据扩充 10 倍(从 88 小时扩充到 827 小时)。通过给定初始帧和语言指令,让模型“脑补”出视频,再用逆动力学模型(IDM)标注伪动作,。这就像让机器人通过“做梦”来进行训练,极大地丰富了长尾场景。
- 潜动作 (Latent Actions): 对于只有视频没有动作标签的人类视频,论文训练了一个 VQ-VAE 来提取“潜动作”,强制让模型学习人类行为的视觉特征,即使不知道具体电机指令也能学到策略,。
- 带来的收益 (Benefit):
- Sim-to-Real: 通过 DexMimicGen 在仿真中低成本生成了相当于 6500 小时的人类演示数据。
- 泛化性: 即使真机数据很少(10%),依靠这种大规模混合预训练,模型也能在未见过的物体和指令上表现出色,。
4. 评测与本质分析 (Evaluation & Comparison)
GR00T N1 不仅是“刷分”,更是验证了 Scaling Law 在具身智能中的有效性。
- 胜出关键: 在仿真 (RoboCasa, DexMimicGen) 和真机 (GR-1 Humanoid) 的多项任务中,GR00T N1 全面超越基线。特别是在低数据微调 (Low-data regime) 场景下,优势巨大。
- SOTA 深度对比 (Critical Comparison):
- Vs. Diffusion Policy (DP):
- 核心差异: DP 通常是从头训练或使用较小的视觉 Backbone (ResNet/ViT),而 GR00T 拥有庞大的 VLM 基座 (Eagle-2)。
- 胜出逻辑 (Why Better?): “小学生 vs. 博士生”。DP 像是一个只学过机械操作的小学生,换个没见过的杯子可能就不认识了;而 GR00T 的 VLM 基座拥有互联网级的常识,具有极强的语义泛化能力。实验显示,在 10% 数据量下,GR00T 胜率是 DP 的 4 倍以上。
- Vs. 纯 VLA 模型 (如 OpenVLA/RT-2):
- 核心差异: 传统 VLA (如 RT-2) 试图将动作离散化为 Token,用同一个 Transformer 统一输出文本和动作。GR00T 采用了解耦设计,VLM 只做推理,DiT 专门做控制。
- 胜出逻辑 (Why Better?): “术业有专攻”。纯 VLA 的离散 Token 难以表达高精度的连续动作,且推理速度受限于 LLM 的解码速度。GR00T 的 DiT 模块不仅能输出连续动作,还能利用 Flow-matching 实现高频控制 (120Hz),更适合对平衡和精度要求极高的人形机器人,。
- Vs. Pi0 (Black et al., 2024):
- 核心差异: Pi0 使用 Mixture-of-Experts (MoE) 架构来桥接 VLM 和动作模块。
- 胜出逻辑: GR00T 选择了更简洁的 Cross-Attention 机制。这种设计更加灵活,允许随意更换 VLM Backbone 或 Action Head,且支持不同实施例特定的 State/Action Projector,更适合多机器人形态的统一。
5. 关键术语对照 (Key Terms)
- System 1 / System 2: 借用认知心理学术语。System 1 指快速、直觉、无意识的反应(动作生成);System 2 指慢速、逻辑、有意识的推理(视觉语言理解)。
- Flow Matching (流匹配): 一种生成模型训练目标,旨在构建从噪声分布到数据分布的确定性路径(向量场)。相比传统扩散模型,通常能以更少的推理步数生成高质量样本,。
- Latent Action (潜动作): 从无动作标签的视频中(如人类视频)学习到的隐空间行为表示,用于监督模型预训练,解决人类视频无法直接用于机器人模仿学习的问题。
- Neural Trajectories (神经轨迹): 使用视频生成模型(Video Gen AI)合成的机器人操作视频,作为一种数据增强手段,极大扩充了训练数据的多样性。
- Action Chunking: 一次推理预测未来一段固定长度(如 16 步)的动作序列,而非只预测下一步。这有助于保持动作的连贯性和平滑性。
6. 总结 (Takeaway)
GR00T N1 是人形机器人迈向“通用智能”的一个重要里程碑。它不仅验证了 “大模型大脑 (VLM) + 扩散模型小脑 (DiT)” 这一混合架构的优越性,更重要的是,它展示了一套完整的数据炼金术——通过混合人类视频、仿真数据和生成式 AI 创造的“神经轨迹”,成功打破了物理世界数据匮乏的诅咒。这表明,未来的机器人竞争,本质上将是数据合成能力与模型架构设计的综合竞争。