6逻辑斯蒂回归
mnist数据集 00:01:43.327 
手写数据的数据集
10个分类 00:02:24.593 
判断y属于集合中的哪一个,这个叫做分类问题 00:06:02.081 
表示他属于某一个类的概率,选择最大的

torchvison包含了一些典型的训练集 train=1-> train train=0 ->test


y的值维0 或1 这个叫做二分类问题





左图被称为饱和函数 00:18:19.386 

将ŷ带入σ(x) 就可以将ŷ 的范围限制在(0,1)
00:20:49.142  sigmid函数的条件: 1. 函数值有极限 2. 单调增函数 3. 饱和函数 logistic是sigmid中最典型的函数,所以约定俗成就用logistic代替sigmid,但实际上sigmid还有很多别的函数
sigmid函数的条件: 1. 函数值有极限 2. 单调增函数 3. 饱和函数 logistic是sigmid中最典型的函数,所以约定俗成就用logistic代替sigmid,但实际上sigmid还有很多别的函数

经过σ(x) 就保证输出值在(0,1)

我们输出的是一个分布,由于我们修改了模型 所以这里的损失计算公式也会发生变化 00:26:29.010 
ŷ表示的就是class=1的概率 1 − ŷ就是class=0的概率 00:30:05.059 

使用下面的公式表示两个分布之间差异性的大小 我们希望这个值越大约好,下面的公式加上了负号

loss越小越好,也就是logŷ越小越好 00:32:26.518 





mini-batch就是对上面的几个loss求均值

没有多大的区别 functional 中包含了σ 其实也就是多个F.sigmoid的函数嵌套
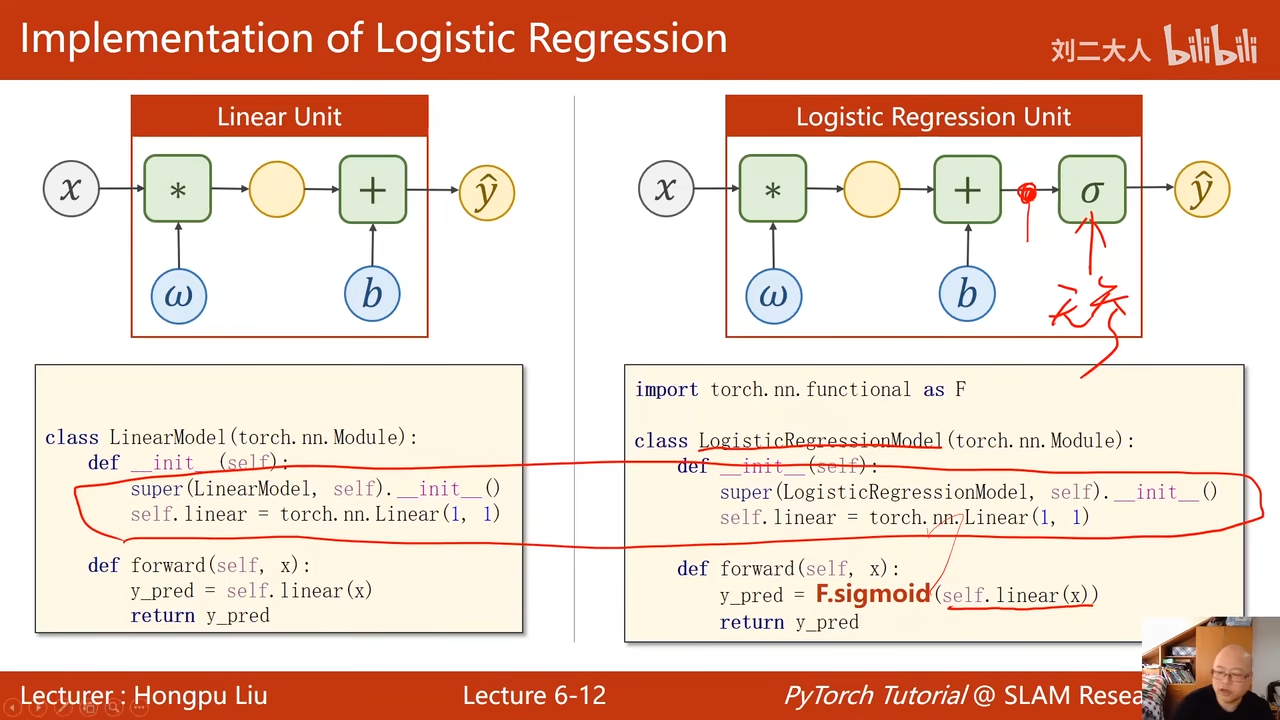
00:36:50.600  损失计算这块的区别是 原来是使用mse 现在是使用bce(二分类的交叉熵) size_average表示是否求均值$\frac{1}{N}$ 这个可能会影响学习率的选择
损失计算这块的区别是 原来是使用mse 现在是使用bce(二分类的交叉熵) size_average表示是否求均值$\frac{1}{N}$ 这个可能会影响学习率的选择

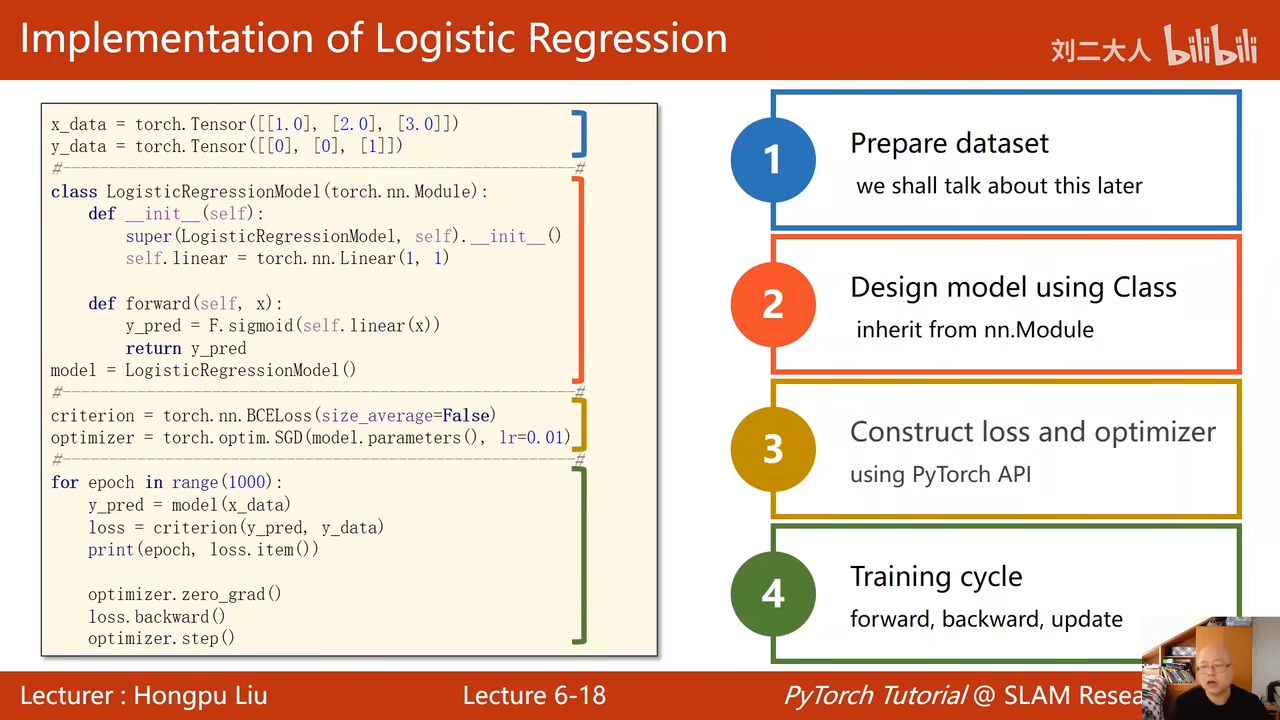
这里回忆一下,model(x_data)这里是调用了call,实现了forward(前馈函数)

绘图 (0,10)个小时取200个点 变成200行1列的矩阵 调用numpy获取数据 然后画图
这个图非常想logist函数