5pytorch实现线性回归
使用随机梯度下降 00:02:18.384 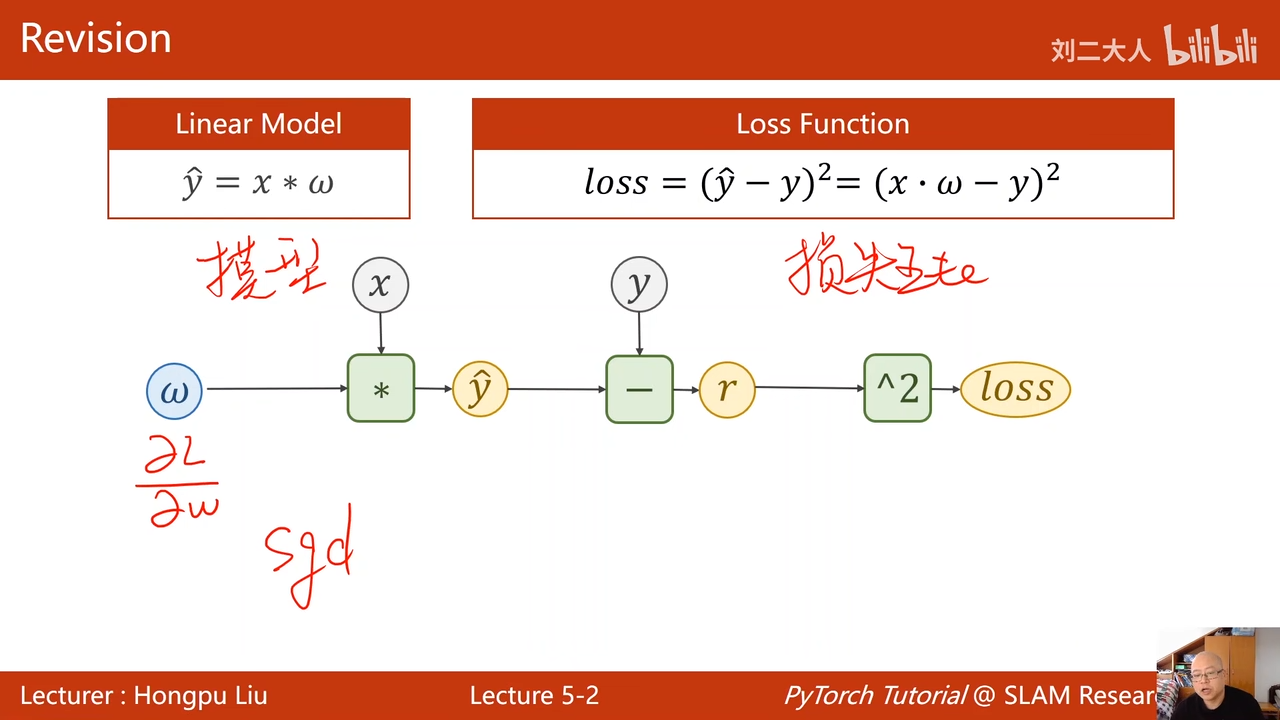
00:03:07.590  上节课的例子 因为梯度不会自动清零,为了使这次的梯度不影响下次的梯度,进行手工清零
上节课的例子 因为梯度不会自动清零,为了使这次的梯度不影响下次的梯度,进行手工清零
线性回归就是恨简单的神经网络
训练步骤: 1. 前馈:算损失 2. 反馈:算梯度 3. 更新:使用梯度下降算法更新权重 00:06:33.097 
00:06:50.802  要使用mini-batch
要使用mini-batch
要一次性将ŷ求出来 所以需要使用矩阵运算
这里运用numpy的广播方式 00:09:36.616 
就是矩阵扩充

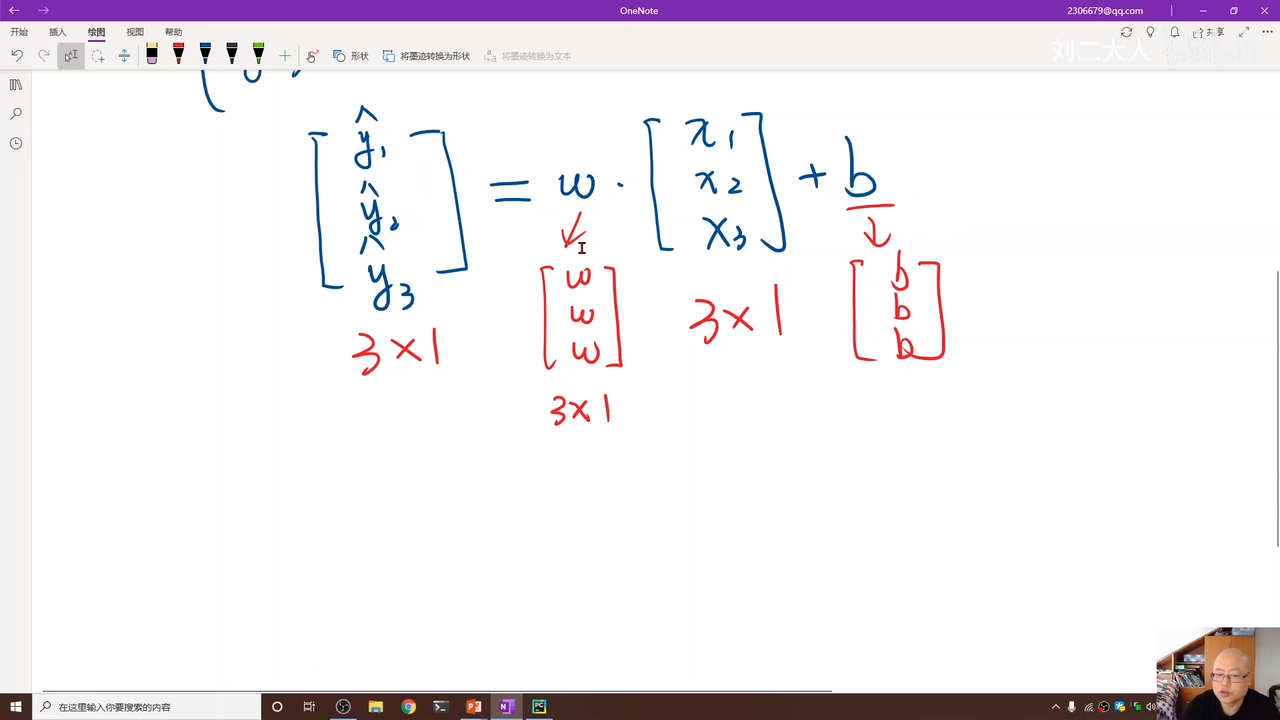
w应该是3x3
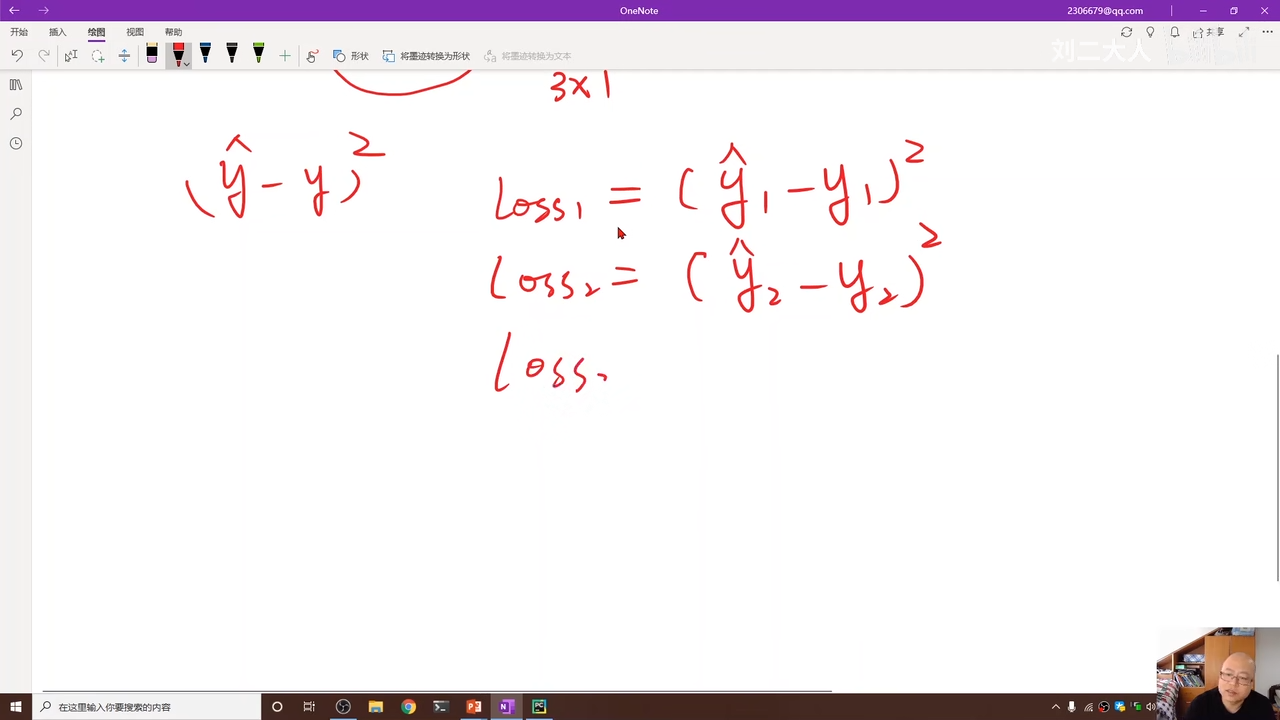

实际上也就是向量化00:12:48.104 



potrch中计算导数不再是重点因为00:13:52.605 
有函数会自动计算导数
重点在于构造计算图00:14:28.914 
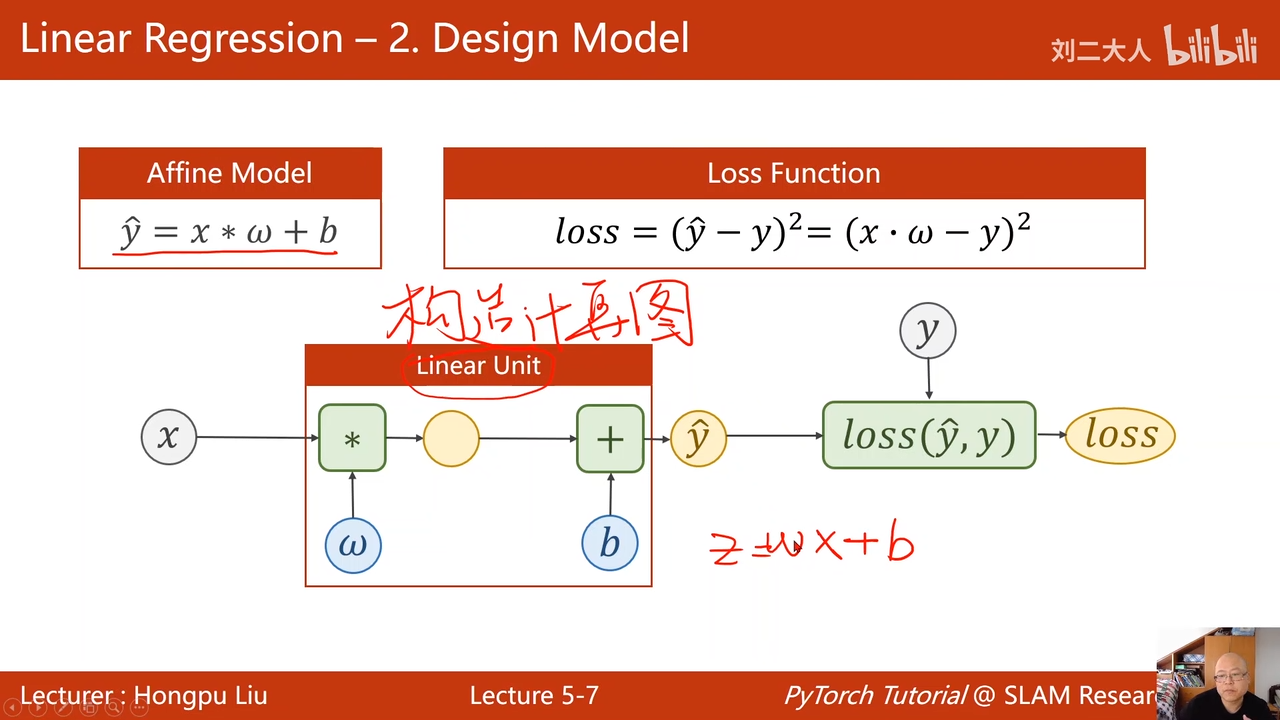
这个被称为一个线性单元

线性模型00:19:45.155 
00:21:21.908  init构造函数:初始化 forward:前馈 反向传播被自动调用 Fuctions是一个类 设计module
init构造函数:初始化 forward:前馈 反向传播被自动调用 Fuctions是一个类 设计module
下面是上节课的代码,而可用于对比 

super就是父类,,第一个参数类的名称 第二个self 实际上就是调用父类的init 这步一定要有
self.linear是在构造对象,00:24:42.264  00:26:15.258
00:26:15.258 
这个对象包含了w和b(也就是权重和偏置) linear也是继承于tensor,所以在使用的时候能构建计算图

这里表示输入样本的维数,输出样本的维数
这里输出、输入样本的维数一定要相等
这里的bias表示是否要b,false就仅为 y = Ax 00:29:38.524 
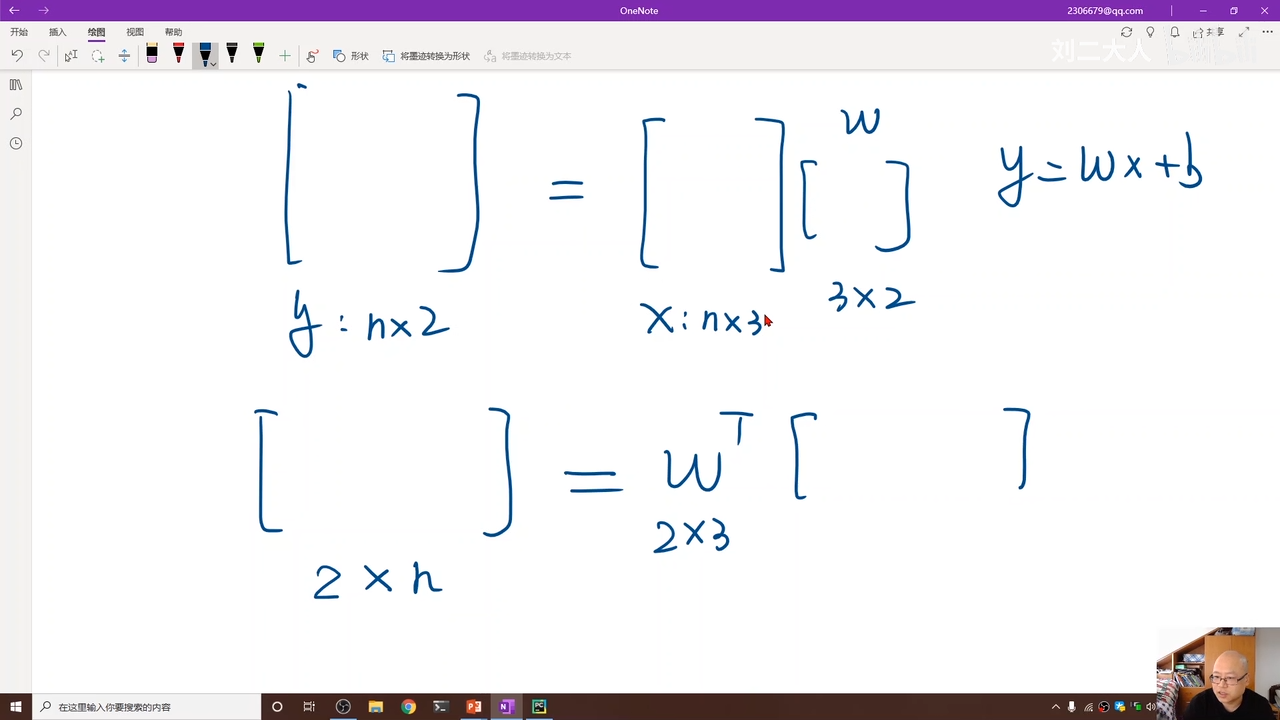

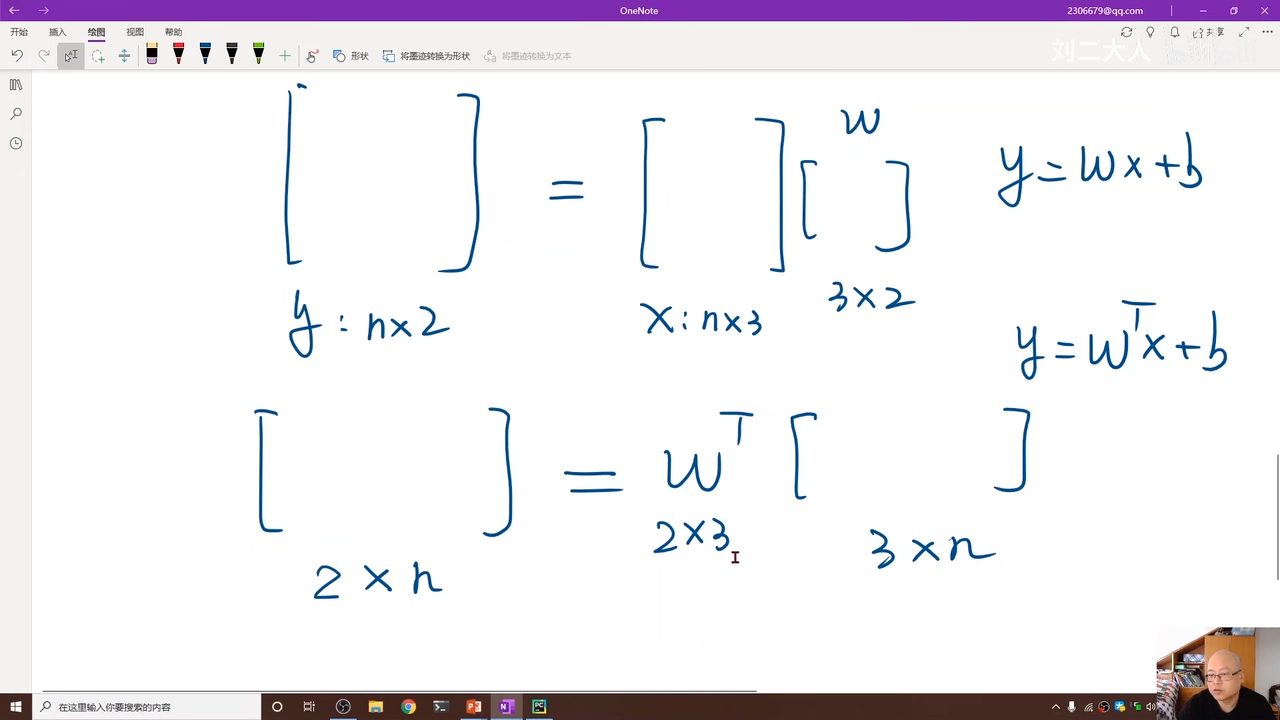
注意上面这个两个的区别,实际上无所谓是哪一种计算方式,只要最后结果是预期的结果就行


塑料英语: 执行了call函数 这个函数让类的例子能够进行反向传播 一般的forward会被调用
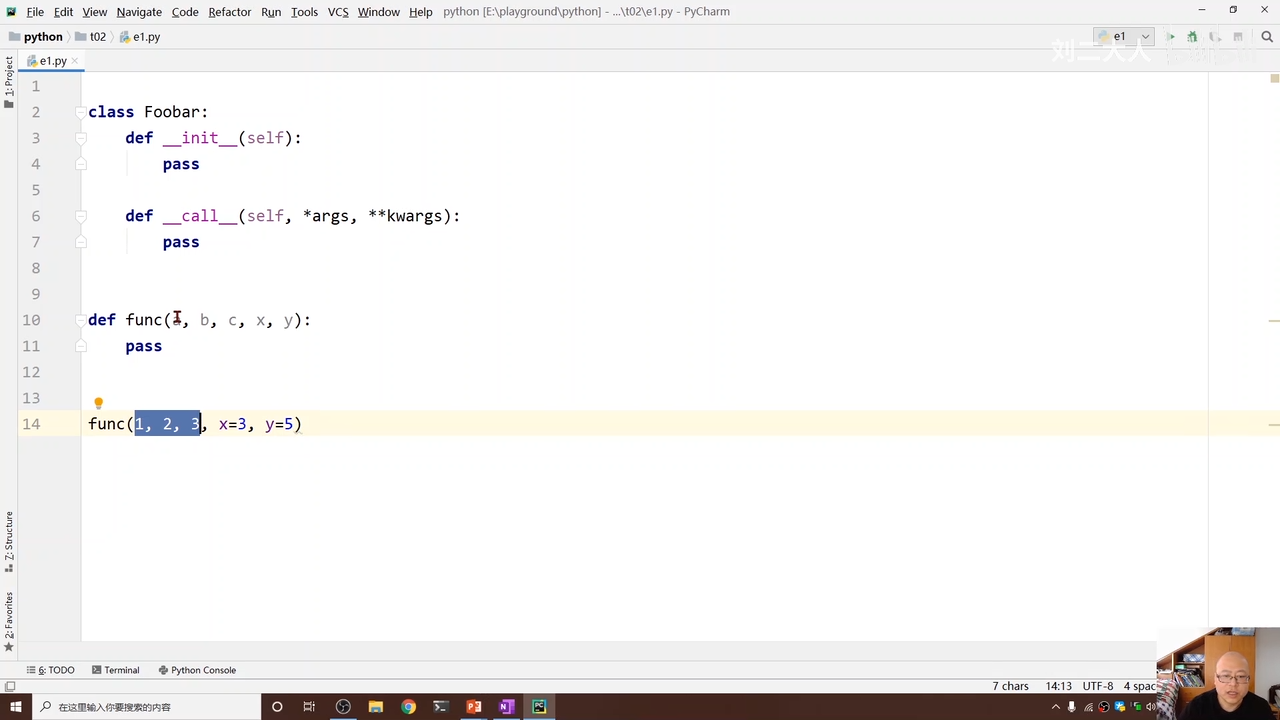
对于前面没有明确注明x=3,y=5的变量,如果不确定输入变量要多少个的时候 出现下面情况 00:33:47.229
 就需要让前面接收变量可变长 00:33:54.002
就需要让前面接收变量可变长 00:33:54.002 
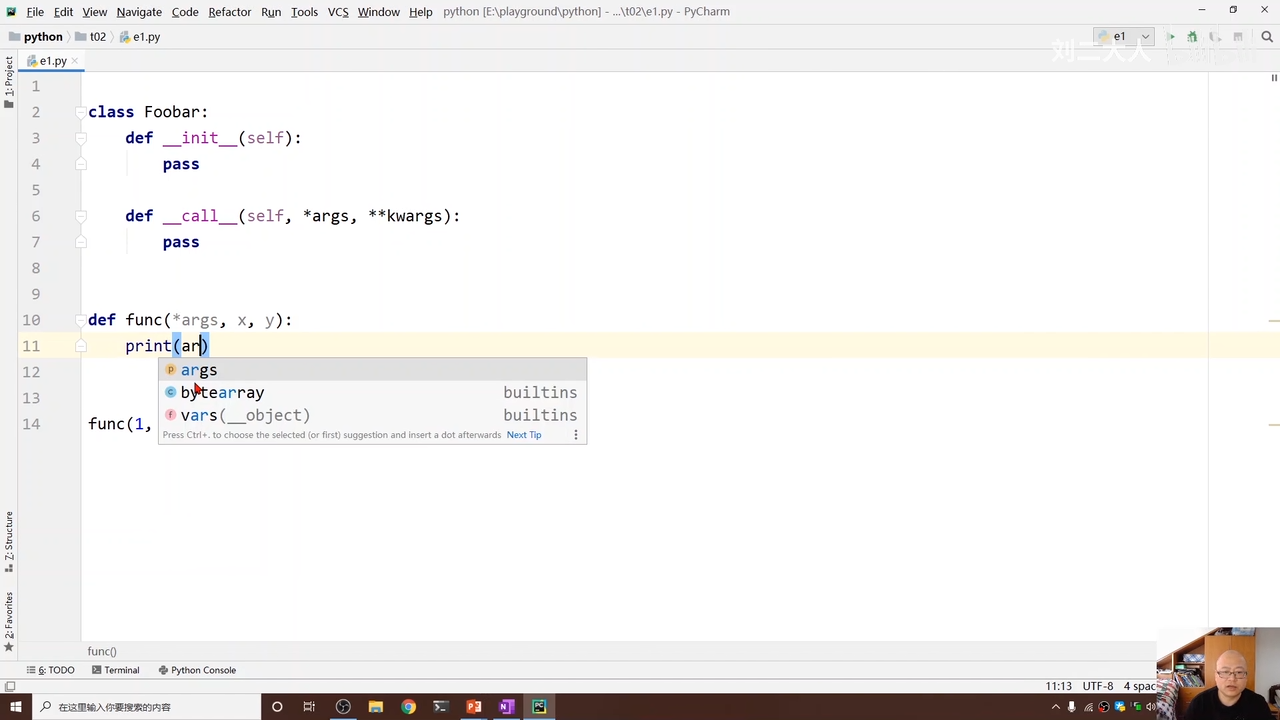
使用这个方法00:34:33.331 

使用这个方式可以实现不管输入多少变量,都可以被存入args中
对于后面指定变量名称的方式 00:34:55.180 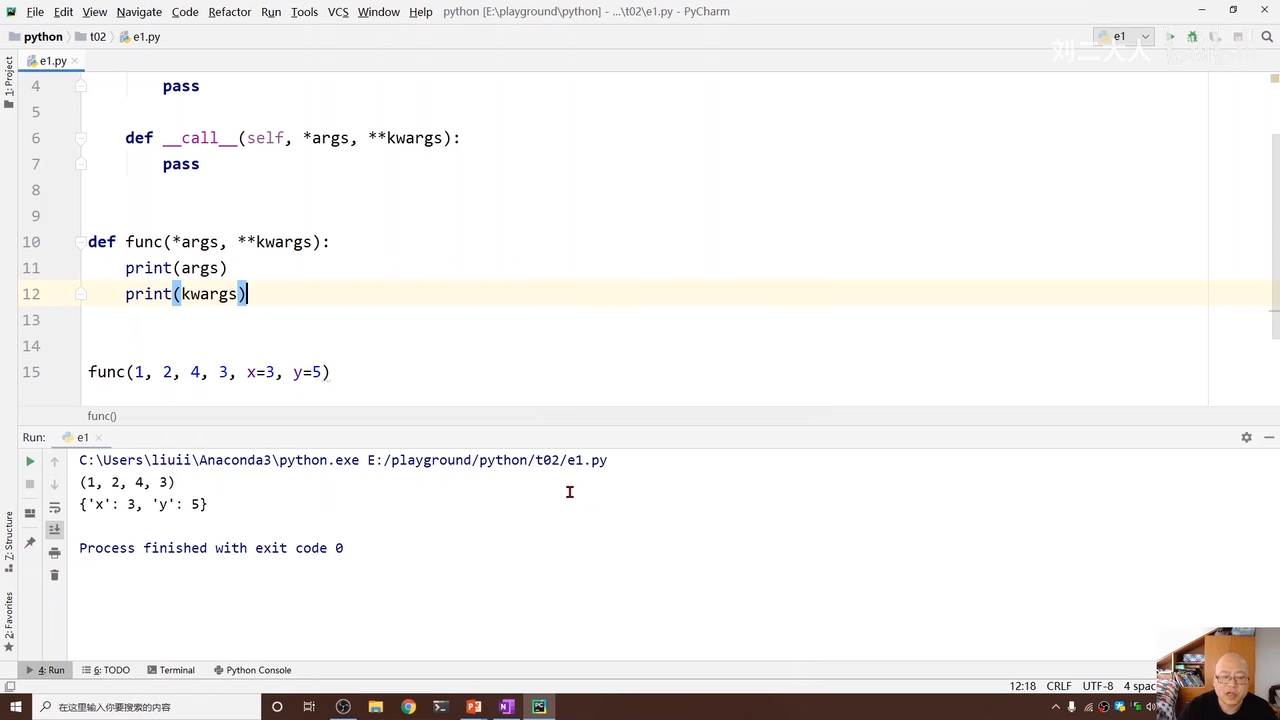
同样实现输入可变长 是以字典的形式来实现 00:35:15.288 00:35:15.288 
通过上面的输出可已看出就是是字典的形式
z1 在moduel的call中,就是放入了forward
在moduel的call中,就是放入了forward

这里实际上就是函数重载, override linearmodel有一个forward 这里重新定义一个forward

类实例化 model是可以直接被调用的 00:38:36.640 
可以直接写model(x),就可直接调用forward
 可以参考这个图
可以参考这个图
00:39:47.751  00:40:03.310
00:40:03.310  00:39:32.224
00:39:32.224  这个损失计算过程可以直接被mesLoss代替
这个损失计算过程可以直接被mesLoss代替

size_avagrage是否求均值 reduce 是否求和,降维成1维其实就是上上图的$\frac{1}{N}$
00:42:17.358  optim这个是优化器 sgd是个类,这里是在进行实例化
optim这个是优化器 sgd是个类,这里是在进行实例化
model.parameters 00:43:07.946 
在model中没有定义权重,使用linear这样的成员 所以parameters就是告诉优化器,哪些tensor对象数需要被==优化==,这里的优化也就是需要实现update,比如进行w权重的更新(一般基于梯度下降)
model的成员函数parameters 会检查model中所有成员 如果成员里有权重,就会把这个权重加到参数集合上
他会基于计算图查找所有嵌套的成员是否有权重 00:45:11.955 

lr是学习率 learning rate 00:45:58.809  可以对不同的部分使用不同的学习率
可以对不同的部分使用不同的学习率


print函数 中的loss自动调用__str__(),不会生成计算图 00:48:00.459 
把所有权重的梯度归零 然后进行反向传播 step函数进行权重更新 00:49:22.738 
- ŷ
- loss
- backward
- 更新w 00:49:53.799

如果不加item,weight是一个矩阵


这里就是让x_test作为tensor对象,其中的数值是4 然后将tensor对象x_test传入model,使用y = wx + b 进行计算
输入输出的都是二倍的关系 由已知的结果分析,w应该是2,而b应该为0 y_pred应该维8 所以这次的结果并不理想 说明训练还没有收敛的很好

后面进行的1000次迭代,实现的结果

上面这个点是过拟合点 红色线是测试集 蓝色是训练集
如果训练次数过多,会有过拟合的风险


- 准备数据集
- 设计模型
- 中间的criterion构造损失函数$\frac{1}{N}(\hat{y}-y)$,后面的是优化器(update)
- 然后是进行训练 00:54:20.540

这里是不同的优化器 sgd优化器是基于随机梯度下降法,进行权重更新的优化器 