2线性模型
深度学习顺序 1. 准备数据集 2. 模型选择 3. 训练 4. 推理 00:01:57.536 


仅有输入的数据,在测试或者推理阶段

数据集交给算法,得到预测算法,使用模型只进行预测

知道输出值-》监督学习
测试集用于评价模型好坏
数据集分成两个部分 00:08:42.608 



深度学习训练最大问题:过拟合 过拟合:把图像中的噪声也学进去了 比如训练集中的小猫都很可爱,但是测试集的小猫不可爱,导致测试中无法准确识别
需要模型有比较好的泛化能力
训练集分成两份 开发集用于对训练集进行评估,防止过拟合 评估比较好好再把所有的训练集重新训练,之后丢给测试集 00:15:00.775 

其实就是找到f(x) 线性模型是最基本的,可以最开始测试是否可用
预测出来的加上y heater 00:20:28.689 
如何找到斜率为2

ŷ(k) − y(k) 偏差值用于评估数据值与实际值之间的偏差



mean是平均loss  00:28:34.368 损失函数 平均平方误差(mse)
00:28:34.368 损失函数 平均平方误差(mse)
00:29:37.160  使用穷举法的思路 就是挨个w计算损失 00:30:41.118
使用穷举法的思路 就是挨个w计算损失 00:30:41.118
 在所有损失中选取最小的 00:32:32.288
在所有损失中选取最小的 00:32:32.288 
前馈函数 00:32:11.320 
数据集保存 输入输出要分开
相同的样本是一类,比如1和右边的0是一对 00:32:22.783

损失函数 00:33:04.537  两个列表用于存放权重和 权重对应的损失值
两个列表用于存放权重和 权重对应的损失值

间隔为0.1 00:33:57.217 
前馈 计算损失 损失值相加,没有均值 00:35:32.139  画图
画图
这个表不很常用
因为上面这个图很难用来判断是否收敛 最常使用epoc(轮数)作为横坐标 00:37:18.063 
00:37:29.365  上面是训练集的图像
上面是训练集的图像
下面红色的是开发集的数据00:37:55.434 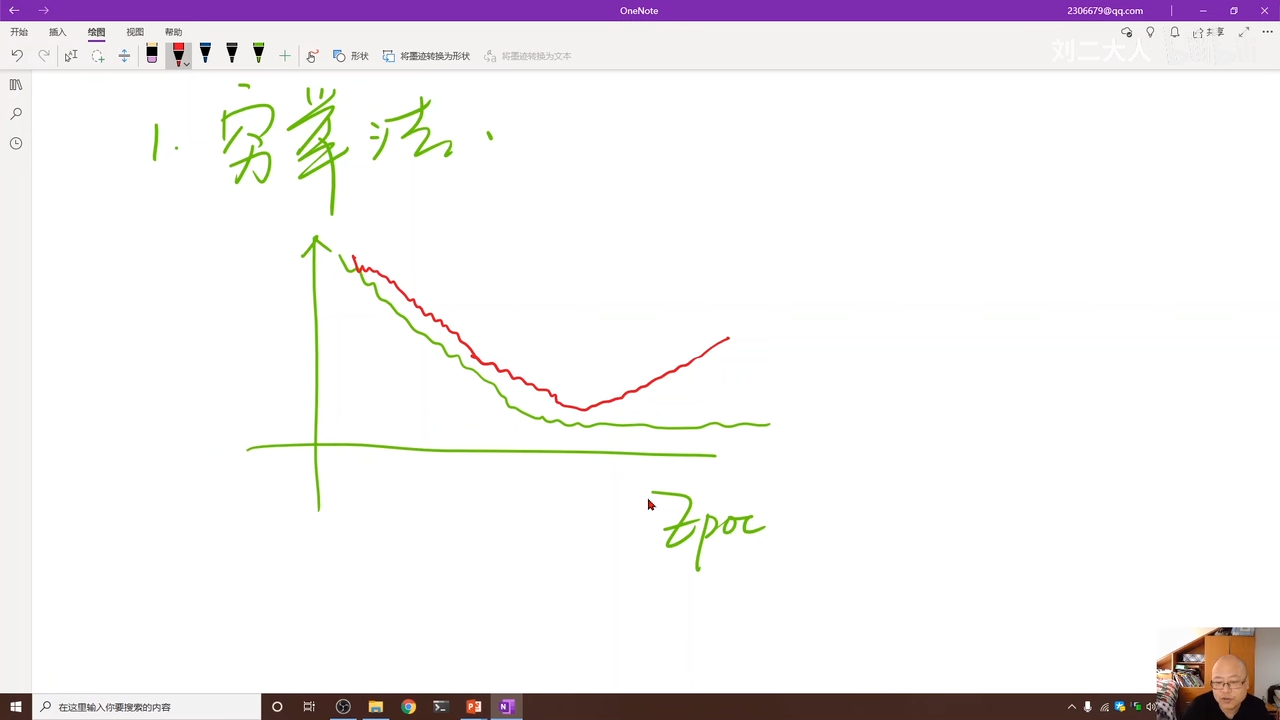

这个点是收敛点
深度学习需要可视化,python绘图
常用visdom

np中的meshgrid()很重要