11卷积神经网络(高级)
之前学习的都是线性的串行结构 就是上一个的输出作为下个的输入
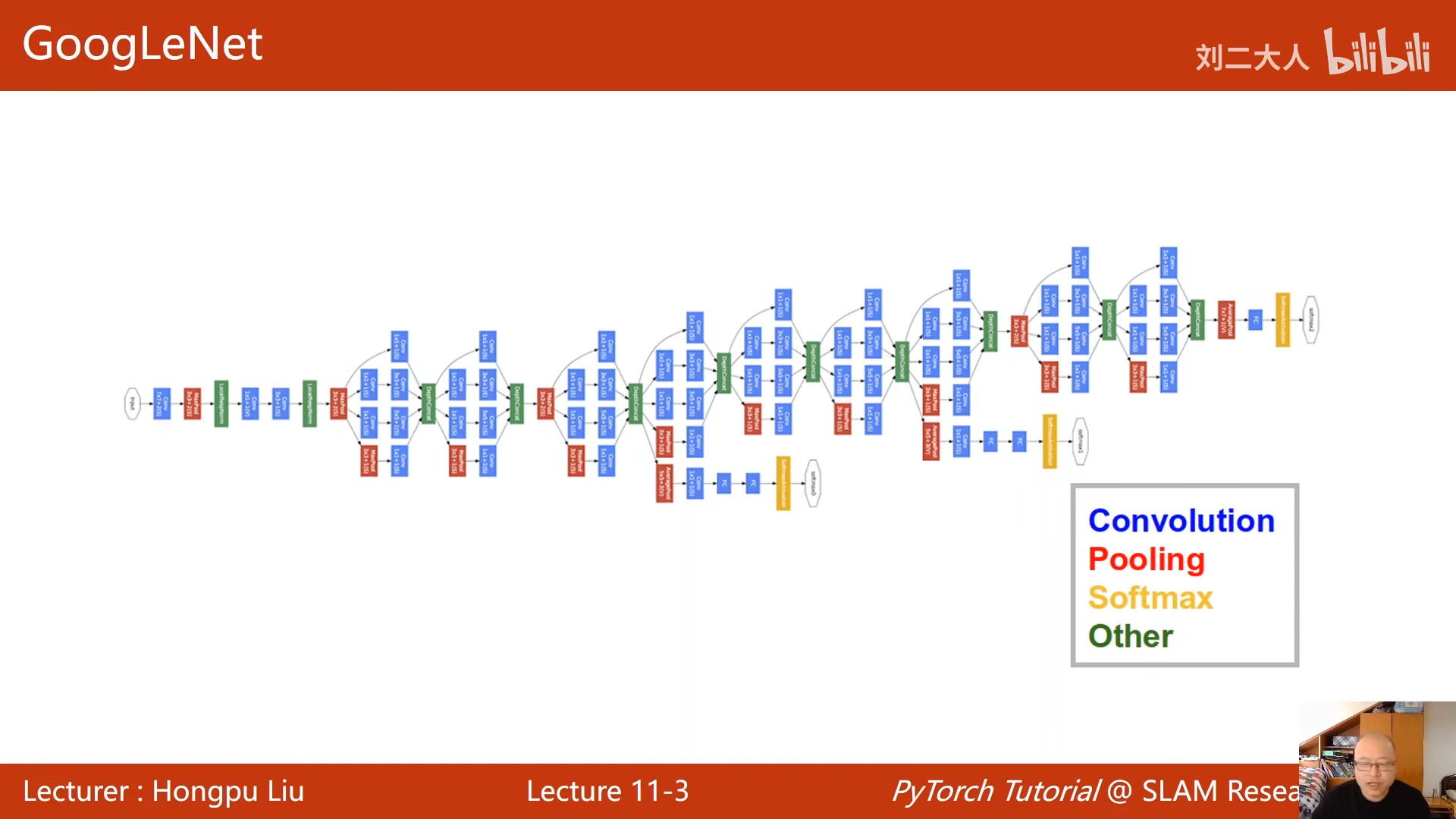
convoltion:卷积 pooling:池化 softmax:输出 other:拼接层
为了减少代码冗余: - 使用函数调用 - 构造类 00:04:05.180 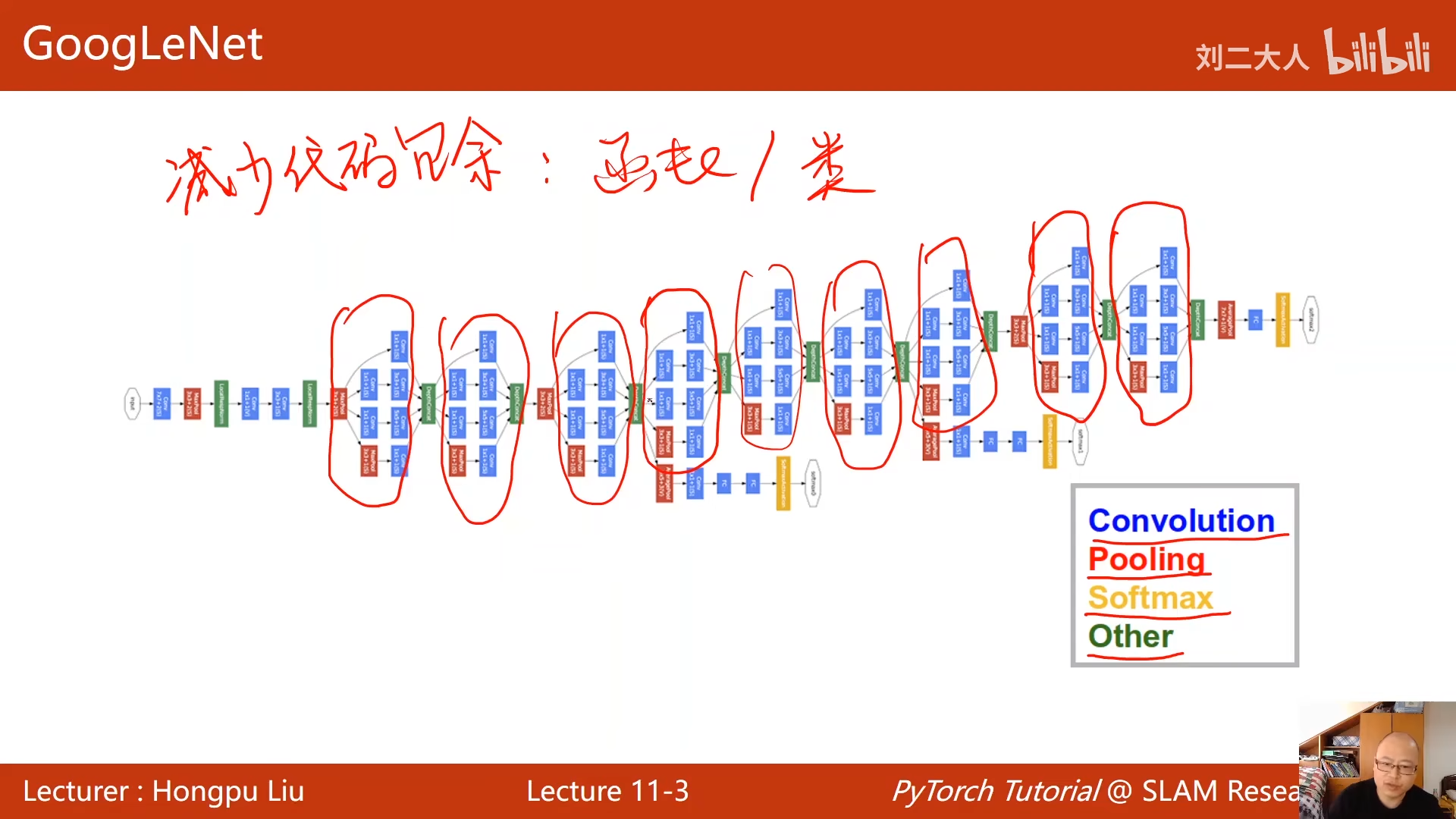
发现这些快长得都一样 所以把其封装成类

有一些参数比较难选 比如kernel选哪个,
googlenet的思路是,再一个块中,使用多个kernnel 然后对结果进行评价,让最优的kernel权重增加

对于每一条路,变换之后bwh必须相同 c可以不同 00:11:39.744 



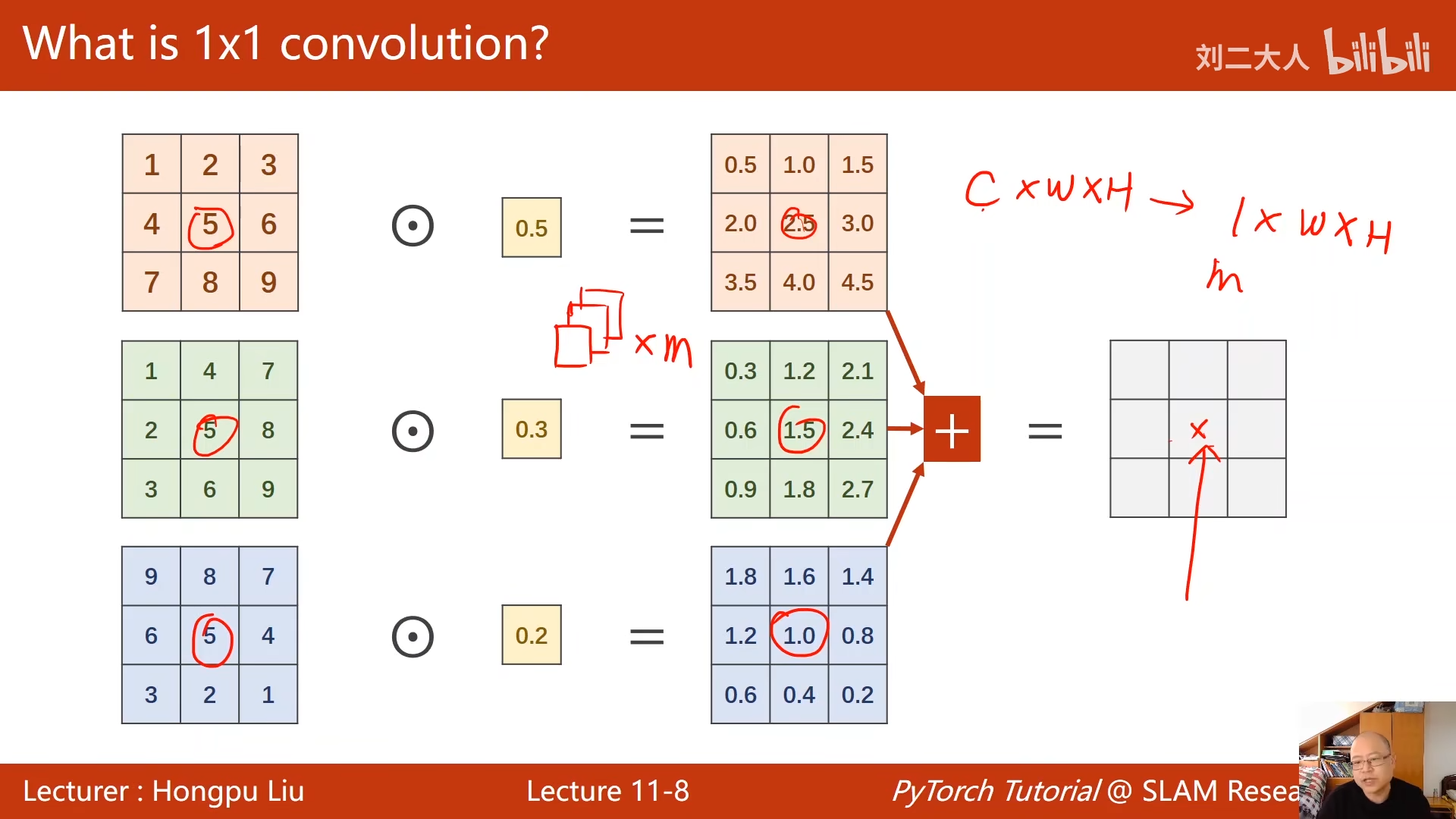
求和也就是信息融合

00:19:24.494 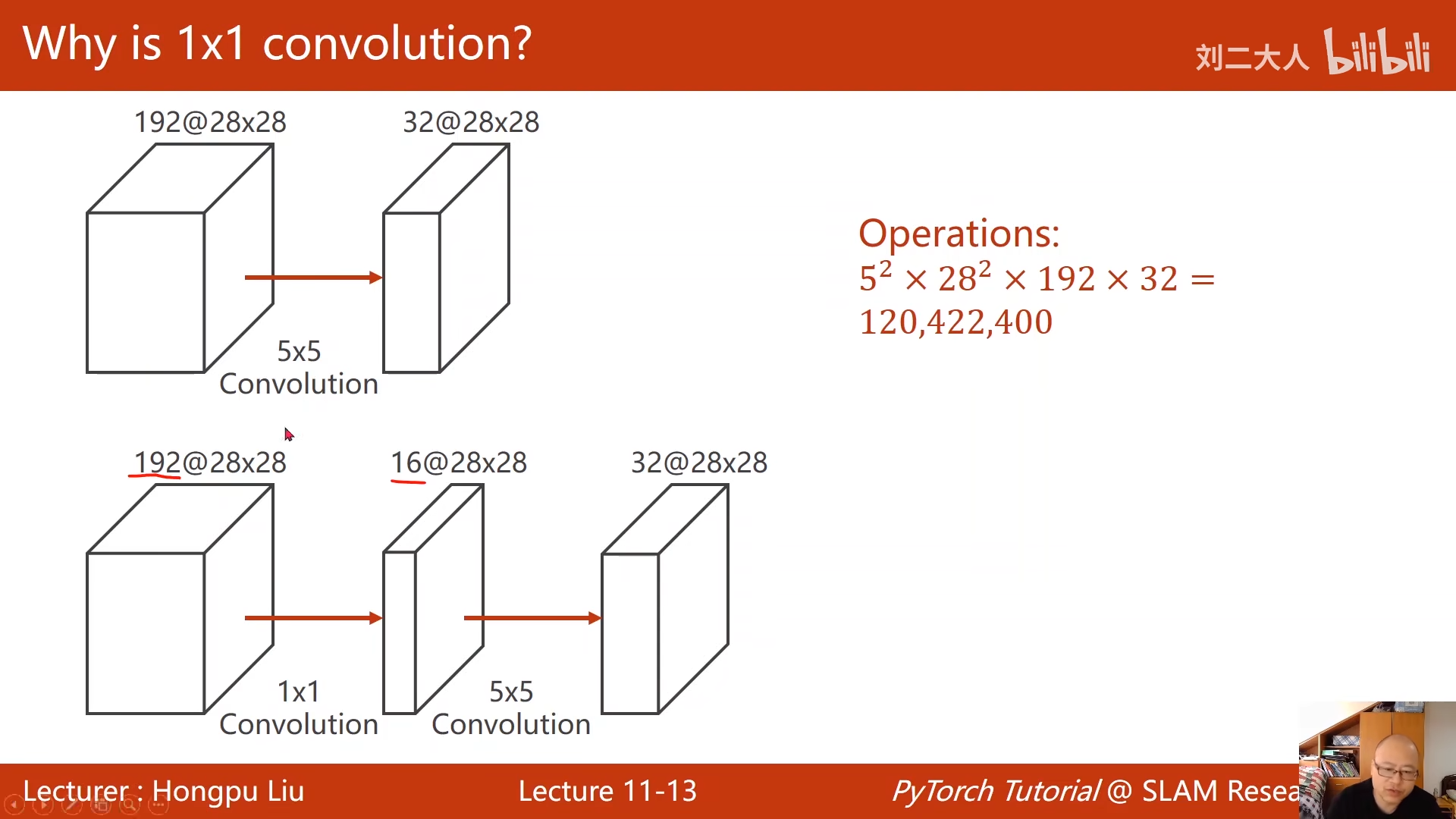 上面这个的运算量太大了
上面这个的运算量太大了
00:20:06.613 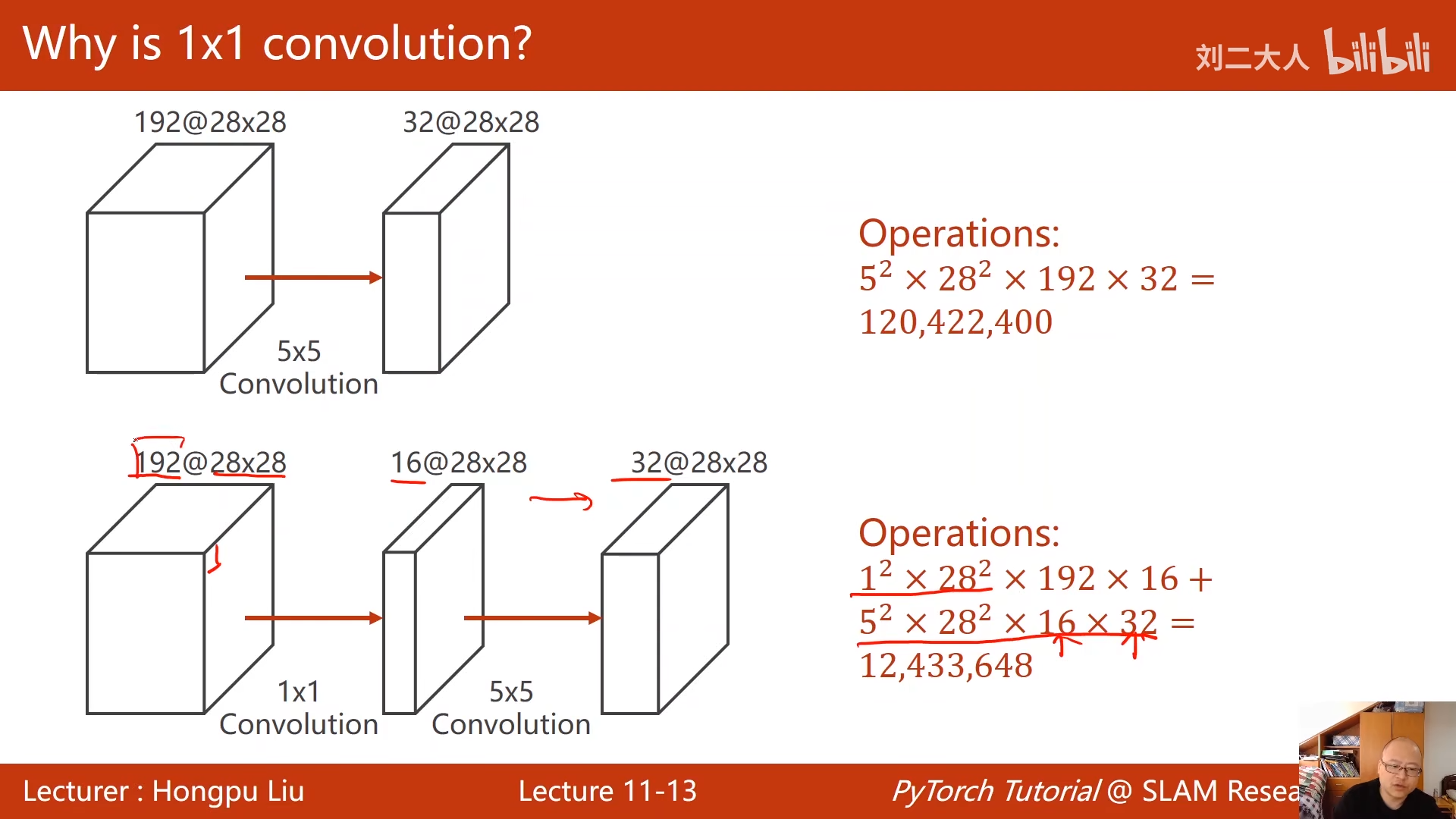 直接变为原来的十分之一
直接变为原来的十分之一
这个也就是1x1的卷积神经网络的作用
网络中的网络:1x1卷积






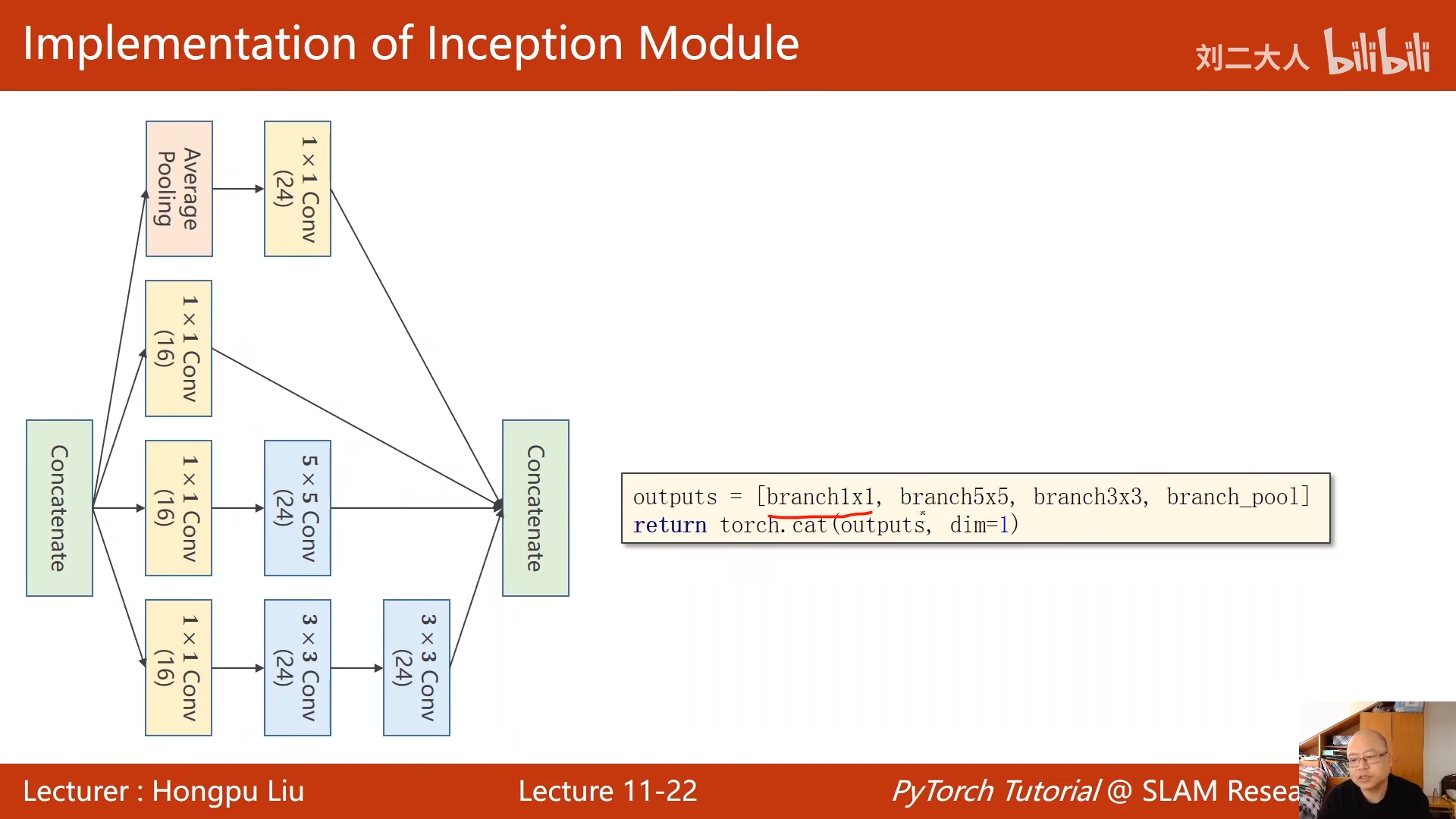


所有的内容整合到一块,形成一个类

右图是构造网络 00:30:37.481 
一共输出88个通道 00:31:02.224

这也是代码中88的由来

最优的是在中间,而不是最后,所以训练轮数不是越多越好 ,后面有过拟合的倾向

对于这种情况的操作是,将最好的版本进行存盘


20层的卷积比56层更好
原因有可能是:梯度消失
当梯度趋近于0时,权重就得不到更新 也就是里输入比较近的块,没办法得到充分的训练
训练神经网络若干个层
解决办法 00:38:46.307 
将每一层进行加锁 算完之后加锁 逐层训练
这个实际上是很难执行的,因为层数很多


跳连接
加完了再激活
重点是和x做加法 这就要求输出F(x)的bchw都需要和x一致 b batch c channel 。。。 00:42:02.763 

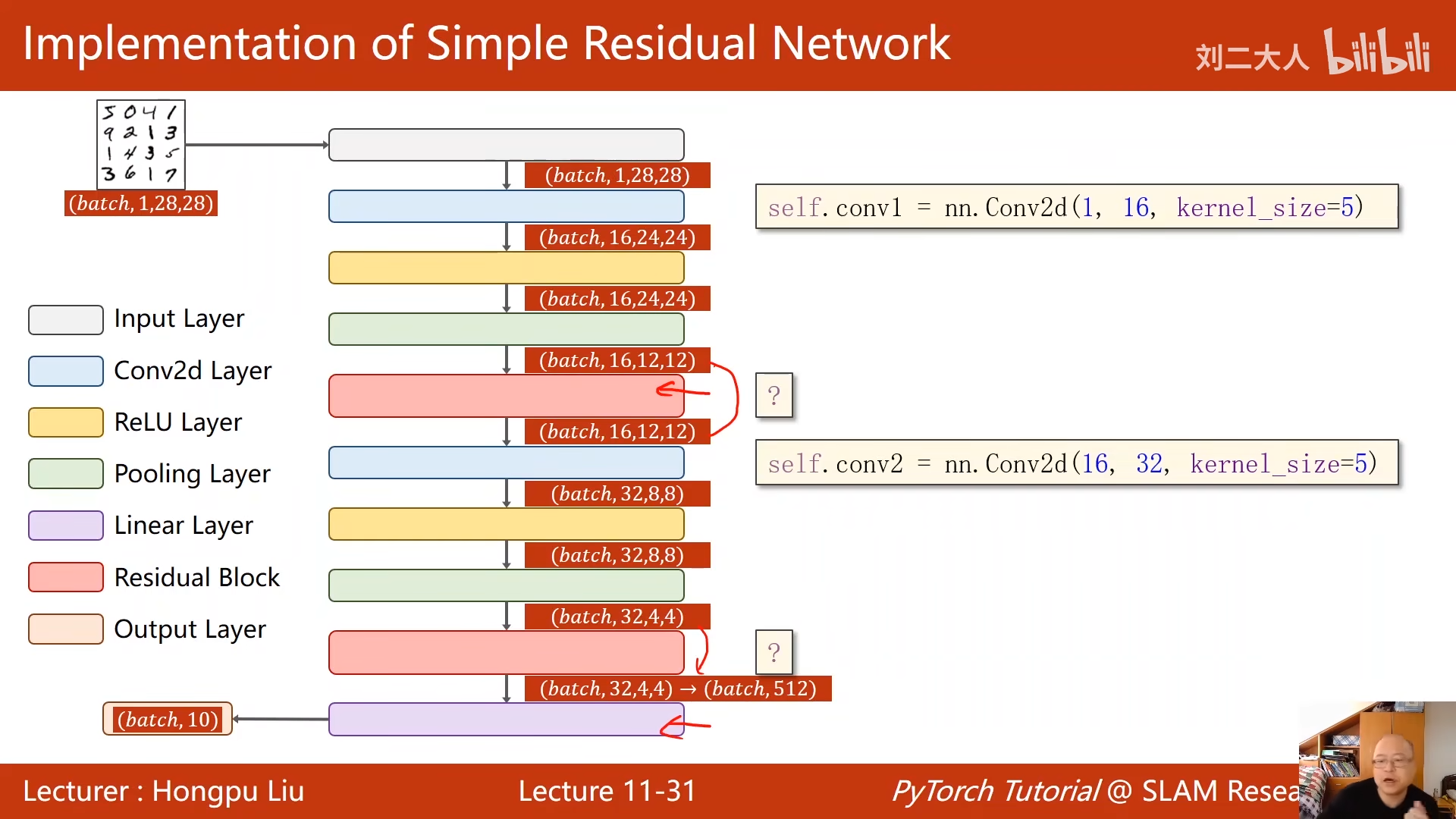

注意最后一步顺序 先求和,再激活



接下来的学习路线 00:53:35.096 

最好通读一遍pytorch 00:54:13.784 
复现一些比较经典的代码 00:54:48.217 
跑通代码不对 应该是读代码,了解架构
然后进行架构的复现,00:56:14.756 


完结撒花