opencv学习
chapter1
读取基本操作
1 | #include <opencv2/imgcodecs.hpp> |
导入图片
可以用
1 | std::string |
也可以命名空间,直接使用,不用写std::string之类的
1 | using namespace cv; |
利用string存储路径
1 | string path = "Resources/test.png"; |
使用mat从路径导入图片
1 | Mat img = imread(path); |
imread
1 | Mat cv::imread(const String&filename,int flags=IMREAD_COLOR) |
- 返回值 Mat 类型, 即返回读取的图像,读取图像失败时返回一个空的矩阵对象(Mat::data == NULL)
- 参数1 filename, 读取的图片文件名,可以使用相对路径或者绝对路径,但必须带完整的文件扩展名(图片格式后缀)
- 参数2 flags, 读取标记,用于选择读取图片的方式,默认值为
IMREAD_COLOR,flag值的设定与用什么颜色格式读取图片有关。如果flag>0 返回一个3通道的彩色图像;flag=0返回灰度图像;flag<0返回包含Alpha通道的加载的图像。
imshow
1 | imshow("Image",img); |
waitKey
1 | waitKey(0); |
1.waitKey()与waitKey(0)都代表无限等待,waitKey函数的默认参数就是int delay = 0, 故这两个形式的本质是一样的,在按下任意键后会退出。
2.waitKey(n),表示等待n毫秒后,关闭显示的窗口。
3.当等待时间内无任何操作时等待结束后返回-1。
4.当等待时间内有输入字符时,则返回输入字符的ASCII码对应的十进制值。
导入视频
创建对象
方法一
用于从文件中读取视频
1 | string path = "Resources/test_video.mp4"; |
方法二
从摄像机中读取视频
方法三
创建捕获对象,通过open打开
1 | cv::VideoCapture VideoCapture; //这里的第二个VideoCapture是一个对象名 |
读取视频图像
1 | cv::Mat frame; |
视频读取之后
可以release关闭视频或者摄像头
1 | capture.release(); |
导入网络摄像头
1 | void main() |
chapter2
全网最全的卷积运算过程_Lucinda6的博客-CSDN博客_卷积运算
高斯模糊
原理
在图形矩阵上对一个核进行加权,将其色深进行加权运算
函数
1 | GaussianBlur(Mat src , Mat dst , Size() , sigmax , sigmay , borderType) |
功能:对输入的图像src进行高斯滤波后用dst输出。
参数:src和dst当然分别是输入图像和输出图像。
size为高斯滤波器内核大小(必须是奇数)
sigmaX和sigmaY分别为高斯滤波在横线和竖向的滤波系数
borderType为边缘点插值类型
| InputArray | src, | 原始图像:channels不限,各通道单独处理;depth应当是CV_8U,CV_16U,CV_16S,CV_32F或CV_64F |
|---|---|---|
| OutputArray | dst, | 目标图像:与原始图像size和type一致 |
| Size | ksize, | 高斯核大小,ksize.width和ksize.height可以不同,但是都必须为正的奇数(或者为0,此时它们的值会自动由sigma进行计算) |
| double | sigmaX, | 高斯核在x方向的标准差 |
| double | sigmaY=0, |
高斯核在y方向的标准差。sigmaY=0时,其值自动由sigmaX确定(sigmaY=sigmaX);sigmaY=sigmaX=0时,它们的值将由ksize.width和ksize.height自动确定) |
| int | borderType=BORDER_DEFAULT |
(像素外插策略,可参考BorderTypes ) |
边沿检测
原理:边缘其实就是找到图像上灰度级变化很快的点的集合。关于寻找变化率大的点,用导数肯定是个不错的选择,但是在计算机中不常用,因为在斜率90度的地方,导数无穷大,计算机很难表示这些无穷大的东西。所以一般使用微分表示变化率。
滤波
目的:去除或者减轻图像噪声的影响(噪声是指一些小点,非目标图像的轮廓)
注:滤波模板必须是奇数,因为模板是偶数的话,卷积出来的结果应该是放在中间的,又由于图像是离散的,这样的结果不方便表示。为了方便处理,滤波模板一般都是奇数个的,如3,5,7 个的。
算子
滤波模板必须是奇数,因为模板是偶数的话,卷积出来的结果应该是放在中间的,又由于图像是离散的,这样的结果不方便表示。为了方便处理,滤波模板一般都是奇数个的,如3,5,7 个的。
不同算子的区别:
主要就是每个方块所代表的点数不同,所表示的权重不同,在进行卷积运算中,对图像的处理效果不同。
分类:
robert算子,sobel,prewitt,laplace,canny
梯度
梯度就是图像的偏导数,表示图像色深在x,y处的变化率
canny边缘检测
1 | void Canny(InputArray image,OutputArray edges, double threshold1, double threshold2, |
- InputArray image:输入图像,即源图像,填Mat类的对象即可。
- OutputArray edges:输出的边缘图,需要和源图片有一样的尺寸和类型。
- double threshold1:第一个滞后性阈值【低阈值】。值越大,找到的边缘越少
- double threshold2:第二个滞后性阈值【高阈值】。
- int apertureSize:表示应用Sobel算子的孔径大小,其有默认值3。
- bool L2gradient:一个计算图像梯度幅值的标识,有默认值false。
1 | void main() |
腐蚀和膨胀
1 | void main() |
1 | void main() |
这两个是基本的形态学操作
功能:
- 消除噪声
- 分割(isolate)出独立的图像元素,在图像中连接(join)相邻的元素。
- 寻找图像中的明显的极大值区域或极小值区域
- 求出图像的梯度
简单来说,腐蚀是将一根线变细,而膨胀是将一根线变粗。
原理
设定一个内核,内核在图像上移动
将局部范围内的最大值应用的是膨胀
将局部范围内的最小值应用的是腐蚀
函数
erode和dilate
1 | void cv::erode( InputArray src, OutputArraydst, InputArray kernel, |
| InputArray | src, | (原始图像:通道数不限,depth必须是CV_8U,CV_16U,CV_16S,CV_32F或CV_64F) |
|---|---|---|
| OutputArray | dst, | (输出图像:size与type与原始图像相同) |
| InputArray | kernel, | (用于膨胀操作的结构元素,如果取值为Mat(),那么默认使用一个3 x 3 的方形结构元素,可以使用getStructuringElement()来创建结构元素。) |
| Point | anchor=Point(-1,-1) |
(结构元素的锚点位置,默认值value(-1,-1)表示锚点位于结构元素中心) |
| int | iterations=1 |
(腐蚀操作被递归执行的次数) |
| int | borderType=BORDER_CONSTANT |
(推断边缘类型,可参考BorderTypes ) |
| const Scalar & |
borderValue=morphologyDefaultBorderValue() |
(边缘值) |
getStructuringElement
getStructuringElement 函数的第一个参数表示内核的形状,我们可以选择如下三种形状之一:
- 矩形: MORPH_RECT
- 交叉形: MORPH_CROSS
- 椭圆形: MORPH_ELLIPSE
而第二和第三个参数分别是内核的尺寸以及锚点的位置。
我们一般在调用erode以及dilate函数之前,先定义一个Mat类型的变量来获得getStructuringElement函数的返回值。对于锚点的位置,有默认值Point(-1,-1),表示锚点位于中心。且需要注意,十字形的element形状唯一依赖于锚点的位置。而在其他情况下,锚点只是影响了形态学运算结果的偏移。
1 | element = cv2.getStructuringElement(cv2.MORPH_CROSS,Size(5,5)) |
1 | //载入原图 |
chapter3
调整尺寸
获取图像尺寸
类中的成员函数Size可以获得
1 | Mat img=imread(path); |
Cols和row获取列和行
1 | cout << "cols " << img.cols << endl; |
改变尺寸
Resize
1 | void resize(InputArray src, OutputArray dst, Size dsize, double fx=0, double fy=0, |
- src:输入,原图像,即待改变大小的图像;
- dst:输出,改变大小之后的图像。
- dsize:输出图像的大小。如果这个参数不为0,那么就代表将原图像缩放到这个Size(width,height)指定的大小;如果这个参数为0,那么原图像缩放之后的大小就要通过下面的公式来计算: dsize = Size(round(fxsrc.cols), round(fysrc.rows))
- fx:width方向的缩放比例,如果它是0,那么它就会按照(double)dsize.width/src.cols来计算;
- fy:height方向的缩放比例,如果它是0,那么它就会按照(double)dsize.height/src.rows来计算;
- interpolation:这个是指定插值的方式,图像缩放之后,肯定像素要进行重新计算的,就靠这个参数来指定重新计算像素的方式,有以下几种:
_ _INTER_NEAREST - 最邻近插值
INTER_LINEAR - 双线性插值,如果最后一个参数你不指定,默认使用这种方法
INTER_AREA - 区域插值,使用像素区域关系进行重采样
INTER_CUBIC - 4x4像素邻域内的双立方插值
INTER_LANCZOS4 - 8x8像素邻域内的Lanczos插值
一个是设置尺寸大小,一个是按比例缩放。
1 | void main() |
1 | void main() |
剪切图像
rect类
1 | typedef struct Rect |
类中的成员函数
1 | //如果创建一个Rect对象rect(100, 50, 50, 100),那么rect会有以下几个功能: |
注意:这里的width和height其实是一个成员变量,不需要加括号调用成员函数获得。
矩形平移和缩放
1 | //还可以对矩形进行平移和缩放 |
裁剪
1 | void main() |
chapter4
生成空白图像
mat类
有几个重载函数

①这里的rows和cols就是行数和列数,其实就是指定了生成Mat类型的尺寸。
②type其实是指生成的图像的深度和通道和个数,我们可以使用已经宏定义好的参数直接设定,比如CV_8UC3就是指每个像素点都能取0-255,共3个通道,也就是BGR图像具体的参数情况如下:
- bit_depth–>bit数,代表图片中每个像素点所占空间的大小,如CV_8UC3,则代表每个像素占8个bit,这里可以取到8/16/32/64。
- S|U|F
S : signed int ,有符号整形型。
U : unsigned int ,无符号整型。
F : float,单精度浮点型。 - C
–> 图片的通道数
1:单通道图像,即为灰度图像。
2:双通道图像。
3:RGB彩色图像,3通道图像。
4:带Alpha通道的彩色图像,4通道图像。
③最后的Scalar,这个单词本来的意思就是标量的,其实就是能存多个double常量(前面带有const标识)的一种结构体,下面是Scalar的定义。
任务实现
生成纯色图片
1 | void main() |
绘制图形
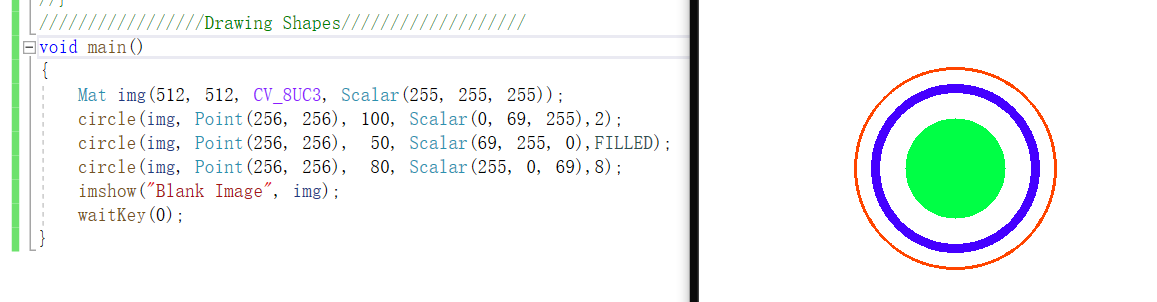
circle
1 | void circle(InputOutputArray img, Point center, int radius, const Scalar& color, |
img:源图像指针
center:画圆的圆心坐标,用Point对象来传参
radius:圆的半径
color:设定圆的颜色,规则根据B(蓝)G(绿)R(红),用Scalar类型
thickness:如果是正数,表示组成圆的线条的粗细程度。默认值是1。-1表示圆是否被填充,我们可以直接用FILLED这个宏定义的参数。
line_type:线条的类型。默认是8。
shift:圆心坐标点和半径值的小数点位数。
1 | void main() |
rectangle
1 | void rectangle(InputOutputArray img, Point pt1, Point pt2, const Scalar& color, |
1 | void main() |

line
1 | void line(InputOutputArray img, Point pt1, Point pt2, const Scalar& color, |

输入文字
1 | void putText( InputOutputArray img, const String& text, Point org, int fontFace, |
- img:显示文字所在图像。
- text:待显示的文字。
- org:文字在图像中的左下角坐标。
- fontFace:字体类型, 可选择字体:FONT_HERSHEY_SIMPLEX, FONT_HERSHEY_PLAIN, FONT_HERSHEY_DUPLEX,FONT_HERSHEY_COMPLEX, FONT_HERSHEY_TRIPLEX, FONT_HERSHEY_COMPLEX_SMALL, FONT_HERSHEY_SCRIPT_SIMPLEX, orFONT_HERSHEY_SCRIPT_COMPLEX,以上所有类型都可以配合 FONT_HERSHEY_ITALIC使用,产生斜体效果。
- fontScale:字体大小,该值和字体内置大小相乘得到字体大小。
- color:文本颜色。
- thickness:文本的粗细。
- lineType:线条类型。
- bottomLeftOrigin:true则图像数据原点在左下角;false则图像数据原点在左上角,默认是false。这两个情况就好像进行了翻转(湖面轴对称),并不是决定org是代表左上角还是左下角。
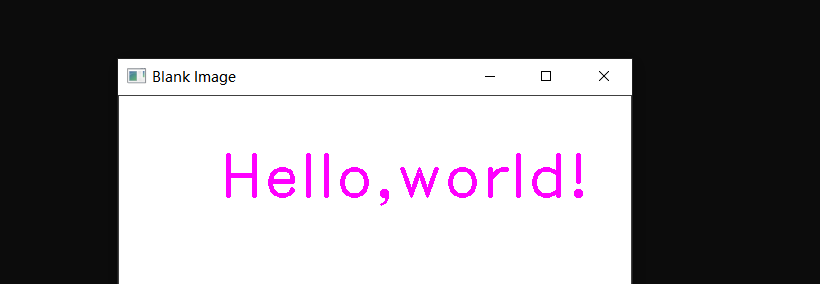
1 | void main() |
chapter5
仿射变换
原理
仿射变换是指在向量空间中进行一次线性变换(乘以一个矩阵)并加上一个平移(加上一个向量),变换为另一个向量空间的过程。利用三个点
实现
1 | Mat getAffineTransform(const Point2f* src, const Point2f* dst) |
首先通过此函数获取变换矩阵
1 | void warpAffine(InputArray src, OutputArray dst, InputArray M, Size dsize, |
然后直接对原图像进行仿射变换
1 | float w = 250, h = 350; |
透视变换
原理
将一个平面通过一个投影矩阵投影到指定平面上,利用四个点
实现
1 | Mat getPerspectiveTransform(const Point2f* src, const Point2f* dst |
首先获取变换矩阵
1 | void warpPerspective(InputArray src, OutputArray dst, InputArray M, Size dsize, |
然后进行透视变换
1 | float w = 250, h = 350; |
chapter6
1、转换为HSV图像模式
我们一般把图像转换为HSV模式,在这个模式下可以更加直观地得到像素点的颜色。
HSV颜色空间中,H是Hue(色度),S是Saturation(饱和度),V是Value(亮度)。色度通常用来从宏观上区分某一种颜色,例如:白、黄、青、绿、品红、红、蓝、黑等就是色度;饱和度指的是颜色的纯度,通常情况下,颜色越鲜艳,饱和度越高;亮度指的是颜色的明暗程度,亮度越高,颜色越亮。
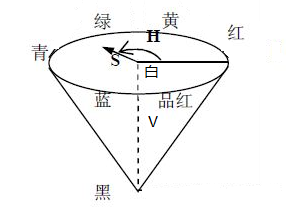
如图所示,某一像素的H可以由该点与白色基准线所形成的圆心角表示,H的取值范围为[0,360];某一点的S可以由该点与所在圆面的圆心之间的距离表示,距离越大,饱和度越高,反之越低;某一点的V可以由该点所在圆面与圆锥顶部之间的距离表示,距离越大,亮度越高,反之则越低。
这里我们还是用cvtColor函数进行色彩模式的转换,从BGR转到HSV模式:
1 | cvtColor(img, imgHSV, COLOR_BGR2HSV); |
2.inrange函数
1 | void inRange(InputArray src, InputArray lowerb, InputArray upperb, OutputArray dst); |
上下阀值这里可以是数组或标量Scalar,其实这两种的原理是一样的,元素的个数应该和通道数是相同的,必须三个通道都满足要求才被设为白色。
实例演示
1 | int hmin = 0, smin = 110, vmin = 153; |
跟踪栏创建
namedwindows
1 | void nameWindow(const string& winname,int flags = WINDOW_AUTOSIZE) ; |
这个函数有两个参数,第一个就是窗口名,第二个是窗口的尺寸,在opencv中已经定义好了一些常量可以使用,一般默认为WINDOW_AUTOSIZE。
- WINDOW_AUTOSIZE 窗口大小自动适应图片大小,并且不可手动更改。
- WINDOW_NORMAL 用户可以改变这个窗口大小。
- WINDOW_OPENGL 窗口创建的时候会支持OpenGL。
当然我们也可以手动设置窗口的大小:
1 | namedWindow("Trackbars", (640, 320)); |
createTrackbar
1 | int createTrackbar(const String& trackbarname, const String& winname, int* value, |
这里我们主要用前四个参数,第一个就是当前滑动栏(滑动空间)的名称,第二个是滑动空间用于依附的图像窗口的名称,也就是刚刚在namedwindows里生成的那个。value是我控制的变量,count就是滑动控件的刻度范围。
我们知道在opencv中,hsv的范围如下:H: [0,179] S:[0,255] V:[0,255]
利用跟踪栏找到上下阈值
1 | namedWindow("Trackbars", (1280, 200)); |
然后依次调整滑动条,使得图像中只有目标图像显示白色
chapter7
图像预处理
首先将图片转换为灰度图片,然后进行高斯模糊,然后通过canny边缘检测,突出边缘特征,进行膨胀操作,让边沿的线更加明显
1 | cvtColor(img, imgGray, COLOR_BGR2GRAY); |
寻找图像轮廓
findcontours
1 | void findContours( InputOutputArray image, OutputArrayOfArrays contours, |
image:输入的单通道图像矩阵,可以是灰度图,但更常用的是经过边缘检测算子处理过的二值化图像。
contours:定义为"vector<vector
hierarchy:定义为“vector
向量hiararchy内的元素和轮廓向量contours内的元素是一一对应的,向量的容量相同。hierarchy向量内每一个元素的4个int型变量——hierarchy[i][0] ~hierarchy[i][3],分别表示第i个轮廓的后一个轮廓、前一个轮廓、父轮廓、内嵌轮廓的索引编号。如果当前轮廓没有对应的后一个轮廓、前一个轮廓、父轮廓或内嵌轮廓的话,则hierarchy[i][0] ~hierarchy[i][3]的相应位被设置为默认值-1。
mode:定义轮廓的检索模式,有下面几种常量取值:
CV_RETR_EXTERNAL:只检测最外围轮廓,包含在外围轮廓内的内围轮廓被忽略。
CV_RETR_LIST:检测所有的轮廓,包括内围、外围轮廓,但是检测到的轮廓不建立等级关系,彼此之间独立,没有等级关系,这就意味着这个检索模式下不存在父轮廓或内嵌轮廓,所以hierarchy向量内所有元素的第3、第4个分量都会被置为-1。
CV_RETR_CCOMP:检测所有的轮廓,但所有轮廓只建立两个等级关系,外围为顶层,若外围的内围轮廓还包含了其他的轮廓信息,则内围内的所有轮廓均归属于顶层。
CV_RETR_TREE:检测所有轮廓,所有轮廓建立一个等级树结构。外层轮廓包含内层轮廓,内层轮廓还可以继续包含内嵌轮廓。
drawcontours
1 | void drawContours( InputOutputArray image, InputArrayOfArrays contours, int contourIdx, |
第一个仍然是要绘制轮廓的图像,第二个就是所有的轮廓,也就是刚刚找到的contours数组,contourIdx则指定要绘制轮廓的编号,如果是负数,则绘制所有的轮廓,后面就是日常的宽度颜色线型。hierarchy表示层级的可选信息,仅用于当你想要绘制部分轮廓的时候,maxLevel表示绘制轮廓的最大层级,若为0,则仅仅绘制指定的轮廓;若为1,则绘制该轮廓及其内嵌轮廓,若为2,则绘制该轮廓、其内嵌轮廓以及内嵌轮廓的内嵌轮廓,依次类推。该参数只有在有层级信息输入时才被考虑。这里默认的INT_MAX,也就是会默认绘制所有内嵌轮廓。
实现项目
1 | Mat imgGray,imgBlur,imgCanny,imgDil; |
coutourArea
获取轮廓内的面积
1 | for(int i=0;i<contours.size();i++) |
形状检测
获取轮廓的周长arcLength
第一个就是轮廓,第二个是一个bool值,表示轮廓是否闭合。
1 | float peri = arcLength(contours[i],true); |
寻找多边形的点和边的特征approxPolyDP
1 | void approxPolyDP( InputArray curve,OutputArray approxCurve,double epsilon,bool closed); |
第一个自然就是要拟合的轮廓点集
第二个就是拟合出来的多边形点集
epsilon是**指定的精度,也即是原始曲线与近似曲线之间的最大距离,0.02*peri**是一个不错的选择
closed和上面一样,表示轮廓是否闭合。
1 | vector<vector<Point>> conPoly(contours.size()); //为了是conPoly和contours一样大 |
绘制边界框boundingRect
此函数用于获得边界矩阵
1 | Rect boundingRect( InputArray array ); |
需要将boundingRect(conPoly[i])再套一层vector,再用rectangle输出边界框
识别图形形状
通过你和出来的轮廓,conPoly[i].size()表示的是图形有几个拐点
1 | int corner = conPoly[i].size(); |
1 | void getContours(Mat imgDil, Mat img) |
其他
vs学习
.sln
.sln 和 .suo都是是解决方案文件。
.sln(Visual Studio.Solution):它通过为环境提供对项目、项目项和解决方案项在磁盘上位置的引用,可将它们组织到解决方案中。
包含了较为通用的信息,包括解决方案所包含项目的列表,解决方案内任何项的位置以及解决方案的生成配置。
比如是生成Debug模式,还是Release模式,是通用CPU还是专用的等。
此文件存储在父项目目录中,他是一个或多个.proj(项目)的集合。
.suo(Solution User Opertion):解决方案用户选项记录所有将与解决方案建立关联的选项,以便在每次打开时,它都包含您所做的自定义设置。
比如VS布局,项目最后编译的而又没有关掉的文件(下次打开时用)。
遇到的问题
配置出现问题
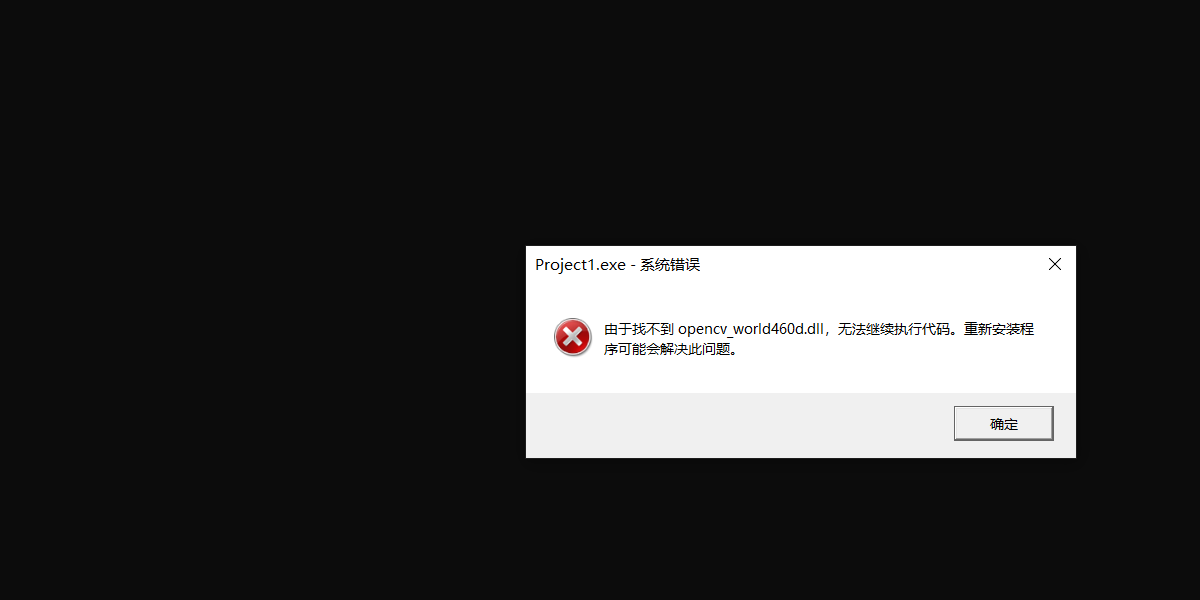
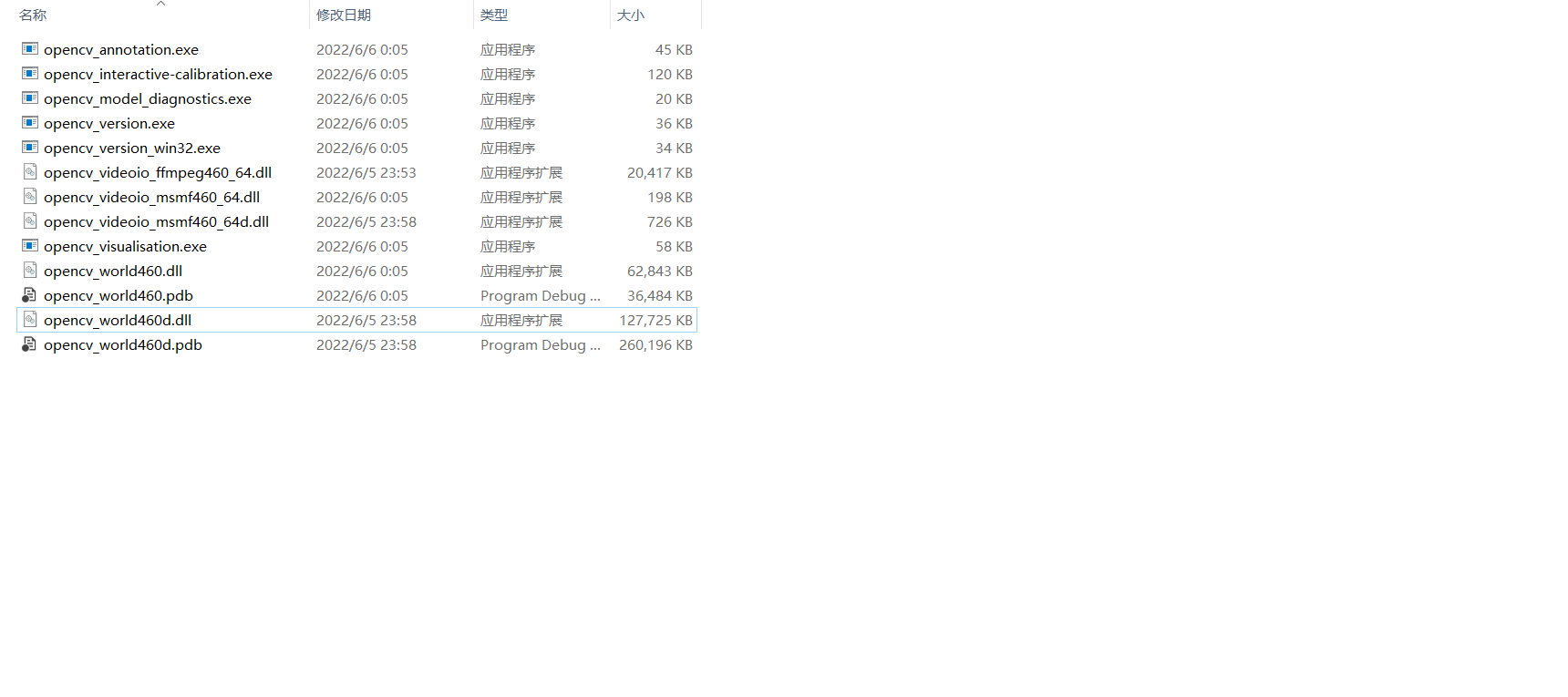
解决办法:
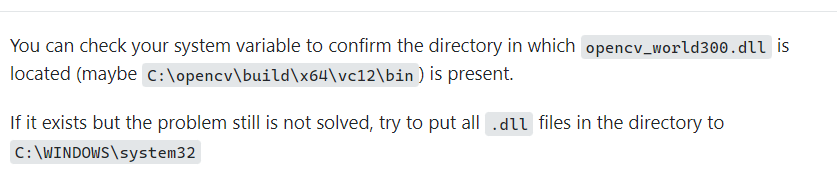

**我的版本是320。设置好所有环境变量后,请确保附加包含目录、附加库目录和附加依赖项都是正确的。对我来说,$(OPENCV_BUILD)
;, $(OPENCV_BUILD);和opencv_world320d.lib;分别。
**我的OPENCV_BUILD路径变量是C:,将环境变量设置为%OPENCV_BUILD%(.dll文件所在的位置)。要获得附加内容,右键单击项目/解决方案并选择属性-> C/ c++为第一个和
视频读取困难
由于视频无法暂停,获取色彩的相关数据比较困难,于是思考寻找可以暂停视频播放的方法,
只有但空格按下时才会播放视频
1 | while (waitKey(0) != 32) |
但此时遇到了新的问题,图像的lower和upper无法输入到mask里面