type
Post
status
Published
date
Dec 4, 2025 20:14
slug
attention
summary
tags
transformer
attention
NLP
category
技术
icon
password
文本
使用ai翻译成中文读了一遍,依旧痛苦,看天书
然后看文字版精读
基于李宏毅老师的transformer课程,notebooklm总结出来的思维导图
学习点:
- 为什么要提出注意力机制,解决了什么问题
在论文中,主要对比的是rnn架构的局限性,从而引出注意力机制。
rnn局限性:
- 并行度低,训练速度缓慢
- rnn是一个线性的结构,后一个的输入是前一个的输出,这个导致在长文本训练时效果比较差。
原因:
在处理文字或语音等序列时,单一词汇的意思往往取决于上下文(Context)。
• 全连接网络的缺陷:如果只单纯将序列中的每一个向量单独输入网络,网络无法利用上下文资讯。例如同一个单词在不同语境下可能是动词也可能是名词,若不看上下文,网络无法区分。
• 固定窗口(Window)的局限:虽然可以强制网络同时看前后几个向量(如前后各5个),但这种方法的范围有限,。若要考虑整句序列,这就需要开一个非常大的窗口来覆盖最长的序列,这会导致参数量爆炸,增加运算量且容易导致过拟合(Overfitting),。
• 注意力机制的解法:Self-Attention 能够摄取整个序列的资讯。它不被局限在一个小窗口内,而是让序列中的每一个向量都能与序列中的所有其他向量计算关联性,从而找出哪些部分是重要的,进而综合全序列的资讯来输出结果,。
3. CNN “感受野(Receptive Field)受限”的问题
CNN(卷积神经网络)也可以用来处理序列或影像。
• CNN 的局限:CNN 的卷积核(Filter)通常只覆盖一个小的区域(感受野)。若要让 CNN 看到整张图片或整个长句子的资讯,必须堆叠很多层网络才能慢慢扩大感受野。
• 注意力机制的解法:Self-Attention 在一层内就可以看遍整个序列或整张影像。它可以被视为一种“复杂化”或“更灵活”的 CNN,其感受野不是人工设定的(如 3x3),而是由网络根据资料自动学习出来的。网络自己决定关注哪些像素或词汇是相关的,。
- 自注意力的输入、计算过程(Query, Key, Value)
query: 查询
key: 键
value: 值
dk: 就是query和key向量长度
这个文章是我目前找到讲解论文最清晰易懂的文章。
Site Unreachable
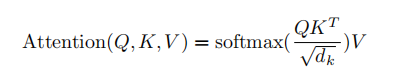
注意力计算的一个例子其实,“注意力”这个名字取得非常不易于理解。这个机制应该叫做“全局信息查询”。做一次“注意力”计算,其实就跟去数据库了做了一次查询一样。假设,我们现在有这样一个以人名为key(键),以年龄为value(值)的数据库:现在,我们有一个query(查询),问所有叫“张三”的人的年龄平均值是多少。让我们写程序的话,我们会把字符串“张三”和所有key做比较,找出所有“张三”的value,把这些年龄值相加,取一个平均数。这个平均数是(18+20)/2=19。但是,很多时候,我们的查询并不是那么明确。比如,我们可能想查询一下所有姓张的人的年龄平均值。这次,我们不是去比较key == 张三,而是比较key[0] == 张。这个平均数应该是(18+20+19)/3=19。或许,我们的查询会更模糊一点,模糊到无法用简单的判断语句来完成。因此,最通用的方法是,把query和key各建模成一个向量。之后,对query和key之间算一个相似度(比如向量内积),以这个相似度为权重,算value的加权和。这样,不管多么抽象的查询,我们都可以把query, key建模成向量,用向量相似度代替查询的判断语句,用加权和代替直接取值再求平均值。“注意力”,其实指的就是这里的权重。把这种新方法套入刚刚那个例子里。我们先把所有key建模成向量,可能可以得到这样的一个新数据库:假设key[0]==1表示姓张。我们的查询“所有姓张的人的年龄平均值”就可以表示成向量[1, 0, 0]。用这个query和所有key算出的权重是:之后,我们该用这些权重算平均值了。注意,算平均值时,权重的和应该是1。因此,我们可以用softmax把这些权重归一化一下,再算value的加权和。这样,我们就用向量运算代替了判断语句,完成了数据库的全局信息查询。那三个1/3,就是query对每个key的注意力。


- 自注意力机制
在深度学习中,Attention 公式通常通用为:
区别完全在于 (查询向量)、(键向量)、(值向量)的来源:
传统 Attention (Cross-Attention)
在机器翻译模型(如 Transformer 的 Decoder 层与 Encoder 交互时):
- :来自 上一个解码层 (Decoder) 的输出。
- :来自 编码器 (Encoder) 的输出。
- 意义: 解码器问编码器:“根据我现在的状态,我该重点看原文的哪里?”
Self-Attention
在 BERT 或 Transformer 的 Encoder 内部:
- :来自 输入序列 。
- :来自 输入序列 。
- :来自 输入序列 。
场景一:普通的注意力机制(就像“翻译官”)
想象你在做一个 中英翻译 的工作。
- 左手边: 是一本中文书(输入)。
- 右手边: 是你的稿纸,你要写英文(输出)。
- 过程: 当你要在右边写 "Apple" 这个词的时候,你的眼睛会回头去看左边中文书里的“苹果”这两个字。
- 本质: 是**“输出”在看“输入”**。因为是两波不同的东西在交互(英文看中文),所以叫普通注意力。
总结:A 看 B(两个不同序列之间的关联)。
场景二:自注意力机制(Self-Attention,就像“侦探破案”)
这次没有翻译任务了,只有一个侦探小组(一句话)在屋子里分析案情。
- 句子: “小明 把 刚买的 手机 摔坏了,因为它 太滑了。”
- 问题: 这里的“它”是指小明?还是指手机?
- 过程:
- 为了搞懂“它”是谁,“它”这个词必须在这一句话内部左看右看。
- 它看到了“滑”这个形容词,又看到了“手机”,发现手机比较容易滑,而小明不太可能“滑”。
- 于是,“它”和“手机”这两个词建立了强烈的联系。
- 本质: 是**“句子里的字”在看“同一个句子里的字”**。大家都是自己人,自己在内部找关系,理顺上下文。
总结:A 看 A(自己看自己,为了搞懂自己内部的逻辑)。
- 意义: 输入序列中的每个词都在问所有其他词:“你们跟我有什么关系?如果你对我重要,我就把你的特征吸取过来。”
- 多头注意力
这块是真的难懂,看了半天还是没看懂
表示有两个需要查询,两头
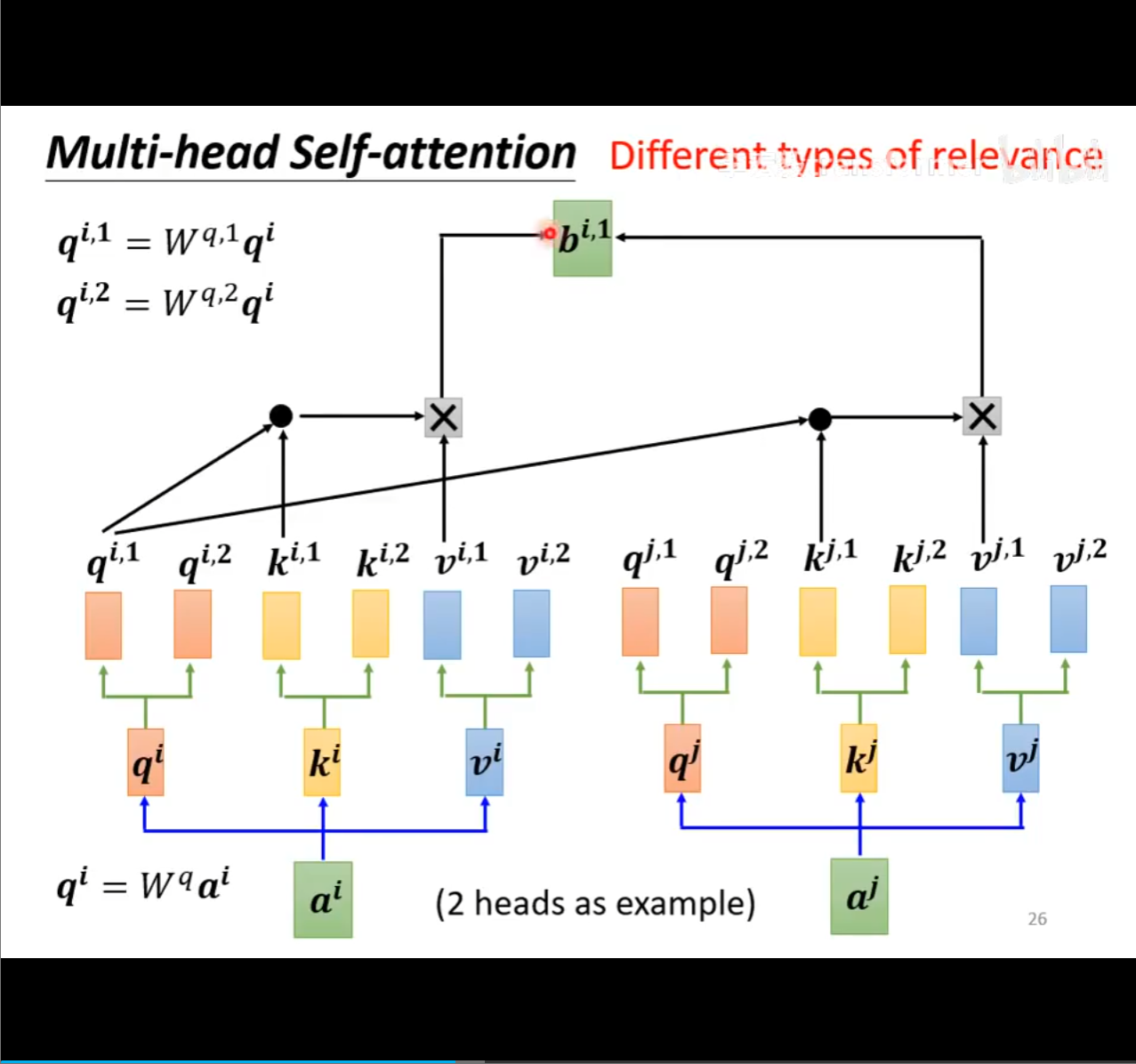
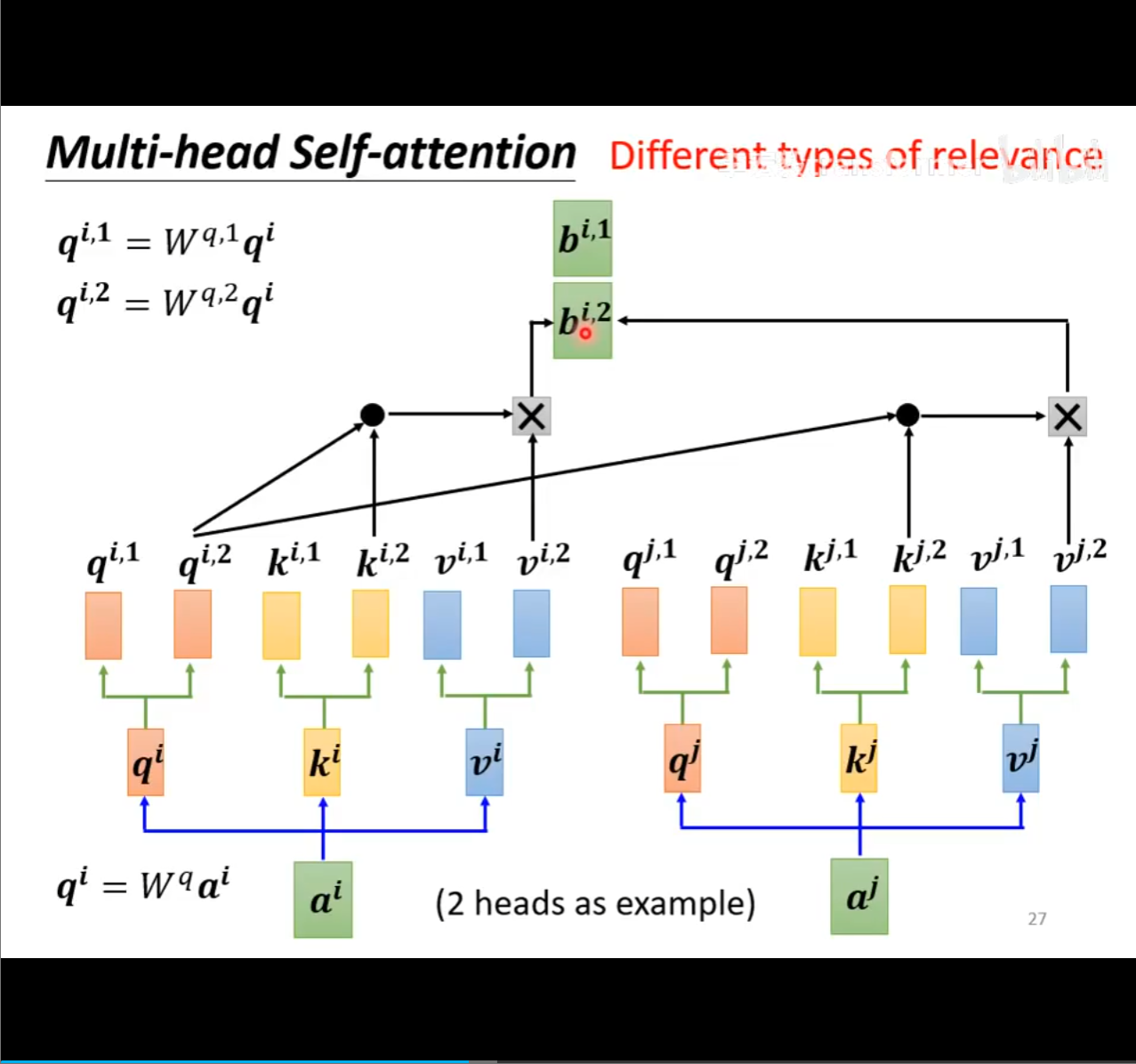
其实就是使用
- 核心比喻:一个人 vs. 一个团队
假设现在的任务是:给一部复杂的电影写一篇完美的影评。
单头注意力(Single-Head Attention)= 你一个人看电影
你非常聪明,但你只有一双眼睛、一个脑子。
- 你看电影时,可能把全部注意力都放在了剧情上。
- 看完后,你写出的影评虽然剧情分析很透彻,但忽略了配乐好不好听、服装漂不漂亮、画面构图如何。
- 局限性: 人的注意力是有限的,顾此失彼。
多头注意力(Multi-Head Attention)= 雇佣一个专家团队看电影
为了写出完美的影评,你不再一个人干,而是雇了 8 个专家(对应 Transformer 默认的 8 个头),大家坐在一起同时看这一部电影。
这 8 个专家分工明确,各看各的:
- 专家 A(Head 1): 只盯着剧情(谁杀了谁,谁爱上了谁)。
- 专家 B(Head 2): 只听背景音乐(是悲伤还是激昂)。
- 专家 C(Head 3): 只看服装道具(是古代还是现代)。
- 专家 D(Head 4): 只关注人物关系(谁是主角,谁是配角)。
- ...以此类推。 第一步:你是怎么拥有“不同视角”的?(切分与投影)
- 用户的疑惑: 为什么同一个向量输入进去,会有不同的理解?
- 实际操作:
- Head 1 的矩阵 (假设它最终学会了关注语法):
- Head 2 的矩阵 (假设它最终学会了关注公司实体):
我们初始化了 8 组完全不同的权重矩阵(这些矩阵里的数字一开始是随机生成的,后来训练出来的)。
得到一组新的 64维向量。这组数据里,可能保留了“名词、单数”的信息,丢掉了其他信息。
得到另一组 64维向量。这组数据里,可能保留了“科技、股票”的信息。
本质: “不同的视角” = “乘以不同的矩阵”。 矩阵就像滤镜,W1 滤出了红色,W2 滤出了蓝色。
第二步:各自计算(并行 Attention)
现在我们有了 8 个不同的 64维向量,它们分别代表“Apple”的 8 种特征。
- Head 1 (语法头): 拿着它的 64维向量去和句子里的其他词比对。它发现 "Apple" (名词) 和 "Released" (动词) 匹配度最高。
- Head 2 (语义头): 拿着它的 64维向量去比对。它发现 "Apple" (品牌) 和 "Phone" (产品) 匹配度最高。
注意: 这一步大家是同时算的,互不干扰。这就对应了比喻里的“专家各看各的”。
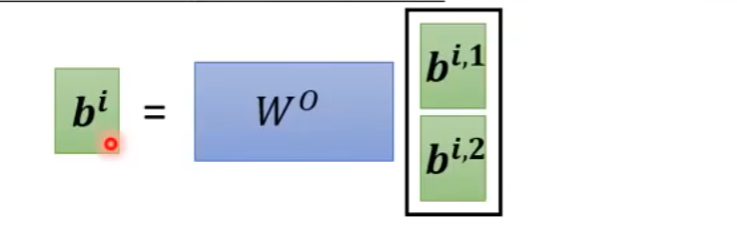
第三步:拼接与融合(Concat & Output)
- 实际操作:
现在 8 个头都算完了,每个人手里都有一个处理后的 64维向量。
我们简单粗暴地把它们首尾相连(拼在一起):
这看起来只是简单的拼凑,所以最后必须跟一个 (输出矩阵) 做一次乘法。
- 为什么要乘 ?
这就好比主编审稿。拼接只是把笔记堆在一起, 负责把 Head 1 发现的语法信息和 Head 2 发现的语义信息融合起来,变成一个综合的上下文理解。
- 交叉注意力
- 自注意力(Self-Attention):是用 A 去筛选 A 自己的信息。(比如分析句子内部关系)。
- 交叉注意力(Cross-Attention):是用 B 去筛选 A 的信息。
一句话总结: 交叉注意力就是让一个数据流(B),根据自己的需要,去另一个数据流(A)里把有用的信息“抠”出来,合并到自己身上。
- Transformer 的整体结构(编码器-解码器)
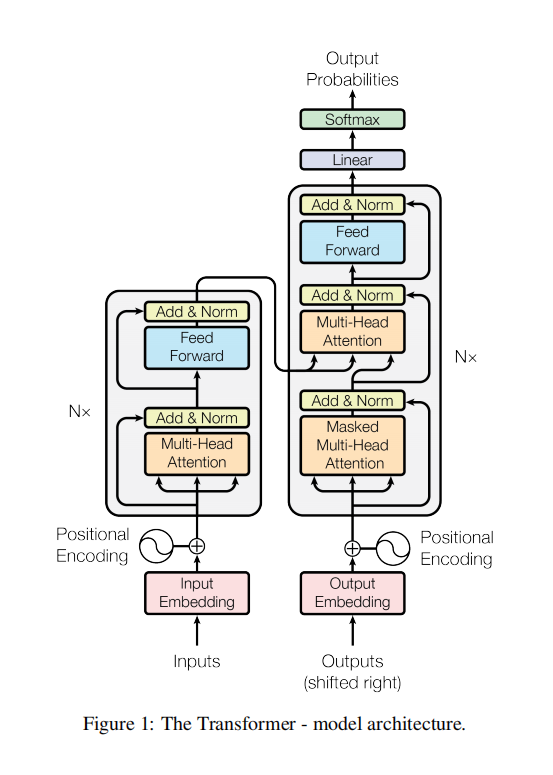
- 左边的柱子:Encoder(编码器) 负责理解输入(阅读)。
- 右边的柱子:Decoder(解码器) 负责生成输出(写作)。 它的任务是:把输入的原始句子(如英文),转化成计算机能完美理解的语义矩阵(Context Vectors)。
encoder
结构特点
Encoder 由 个(通常是 6 个)完全相同的层(Layer)堆叠而成。
每一层里有两个核心组件:
- 多头自注意力 (Multi-Head Self-Attention):
- 由谁看谁? 句子里的词看句子里的其他词。
- 有无限制? 无限制(Bi-directional)。模型能同时看到“过去”和“未来”的词。处理 "Tom hit Jerry" 时,Tom 瞬间就能知道 Jerry 被打了。
- 前馈神经网络 (Feed-Forward Networks - FFN):
- 负责把注意力提取到的特征进行进一步的非线性变换和整合。
数据流向
Input (英文) Positional Encoding [Self-Attention + FFN] x N Encoder Output (Memory)关键产出: Encoder 最终输出的那个矩阵,就是我们之前讲交叉注意力时的 (Key) 和 (Value)。它包含了输入句子的所有精华信息。
2. 右柱子:Decoder(解码器)—— 谨慎的创作者
它的任务是:根据 Encoder 给的“精华信息”和目前已经写好的字,预测下一个字。
结构特点
Decoder 也是由 个层堆叠而成。但每一层比 Encoder 多了一个组件,变成了三个:
- 带掩码的自注意力 (Masked Self-Attention) —— 关键区别:
- 由谁看谁? 已经生成的中文词,看前面的中文词。
- 有无限制? 严格限制(Masked)。
- 为什么? 比如训练时,正确答案是 "我 爱 AI"。当模型读到 "我" 的时候,我们决不能让它偷看到后面的 "爱"。所以我们用一个掩码矩阵(Mask)把后面的词盖住(设为负无穷大),强迫模型只能根据上文猜下文。
- 交叉注意力 (Cross-Attention):
- 这就是之前解释的“桥梁”。
- Q 来自 Decoder 刚才算出来的状态。
- K, V 来自 Encoder 的 Output。
- 作用: 回头看一眼原文,确保翻译准确。
- 前馈神经网络 (FFN):
- 处理特征,准备输出。
数据流向
Input (已生成的中文) Positional Encoding [Masked Self-Attn + Cross-Attn + FFN] x N Linear + Softmax Output Probability (下一个词)3. 整体协作流程(以翻译为例)
假设我们要把 "Hello" 翻译成 "你好"。
Step 1: Encoder 工作(一次性做完)
- 输入 "Hello"。
- Encoder 疯狂计算,输出一个包含了 "Hello" 语义的矩阵 Memory ()。
- Encoder 的工作结束,站在旁边提供资料。
Step 2: Decoder 开始逐字生成(循环做)
- 第 1 轮:
- 输入:起始符
<SOS>(Start of Sentence)。 - Masked Attention:
<SOS>只能看自己。 - Cross Attention:拿
<SOS>的向量去查 Memory,发现原意是问候。 - 输出预测:“你”。
- 第 2 轮:
- 输入:
<SOS>+ “你”。 - Masked Attention:“你”看前面的
<SOS>,明确语境。 - Cross Attention:拿着“你”去查 Memory,结合原意。
- 输出预测:“好”。
- 第 3 轮:
- 输入:
<SOS>+ “你” + “好”。 - ...流程同上...
- 输出预测:
<EOS>(End of Sentence,结束符)。
4. 这种结构的变体(现在的模型都不太一样)
虽然这是 Transformer 的祖师爷结构,但现在的大模型通常只取其中一半:
- Encoder-Only (仅编码器架构):
- 代表作: BERT。
- 特点: 扔掉了 Decoder。
- 用途: 只需要“理解”,不需要“生成”。比如做文本分类、情感分析。它能同时看到所有词,理解力最强。
- Decoder-Only (仅解码器架构):
- 代表作: GPT 系列 (GPT-3, GPT-4, DeepSeek 等)。
- 特点: 扔掉了 Encoder 和 Cross-Attention。
- 用途: 把所有输入直接拼在前面,用“接龙”的方式生成。比如把 "Translate Hello: " 作为一个 Prompt 输入,让它接着写 "你好"。这是目前生成式 AI 的主流。
- Encoder-Decoder (完整架构):
- 代表作: T5, BART, 以及你感兴趣的 Robotics VLA 模型 (如 RT-2)。
- 用途: 经典的序列到序列 (Seq2Seq)。VLA 模型通常用 Encoder 处理图像 (ViT),用 Decoder 生成机器人动作指令。
总结图谱
- Encoder = 资深阅读者(全向视野,产出 K/V)。
- Decoder = 资深作家(单向视野,产出 Q)。
- 连接点 = Cross-Attention。
- 为什么 Transformer 在 NLP 和 CV 中表现优秀
- 核心优势:全局感受野 (Global Receptive Field)
这是 Transformer 最“降维打击”的能力。
- 在 NLP 中 (对比 RNN/LSTM):
- RNN 的痛点: 它是按顺序一个字一个字读的。如果句子很长,读到最后时,开头的记忆已经模糊了(梯度消失问题)。它很难处理长距离依赖。
- Transformer 的解法: 因为 Self-Attention 是并行的,它在处理第 1 个字的时候,就能直接看到第 100 个字。无论句子多长,任意两个词之间的“距离”都是 1。这让它极其擅长理解长文本和复杂的指代关系。
- 在 CV 中 (对比 CNN):
- CNN 的痛点: 它的卷积核通常很小(比如 )。这意味着它一次只能看清一个个局部的小方块。想要把“左上角的鸟头”和“右下角的鸟脚”联系起来,需要堆叠很多层网络,慢慢扩大视野(感受野)。
- Transformer (ViT) 的解法: 它把图片切成 Patch(小块)后,直接计算所有 Patch 之间的注意力。这意味着,模型在第一层就能把整张图看遍,直接建立全局的几何联系。
- 数学本质:归纳偏置 (Inductive Bias) 的减少
这是一个比较学术但非常关键的点。
- 什么是归纳偏置?
- CNN 的假设: 相邻的像素一定相关(局部性),图片平移后还是一样的(平移不变性)。
- RNN 的假设: 时间顺序是至关重要的。
就是模型设计者预先强加给模型的“假设”。
- Transformer 的做法:
- 缺点: 在数据量少的时候,它学得慢(因为它什么都要从头学,不知道相邻像素应该一起看)。
- 优点: 在数据量极大时(大模型时代),它不受限于人类设定的规则。它能学到比“局部相关性”更复杂、更本质的特征。
Transformer 几乎没有这些假设。它不假设相邻的词更相关,也不假设像素的空间关系。
- 计算机制:动态权重 vs. 静态权重
这是 Transformer 在 CV 领域击败 CNN 的具体数学原因。
- CNN (卷积神经网络):
训练好之后,卷积核(权重矩阵)是固定的。无论输入是一只猫还是一辆车,卷积核都用同一组参数去扫描图片。这叫“内容无关 (Content-independent)”。
- Transformer (注意力机制):
- 如果你给它一张猫的图,它会根据数据计算出一组权重,重点关注猫耳朵。
- 如果你给它一张车的图,它会算出另一组完全不同的权重,重点关注车轮。
- 这叫“内容自适应 (Content-adaptive)”。
Attention Map 是根据输入数据动态生成的。
这种根据输入调整处理方式的能力,使得 Transformer 的表达上限远高于 CNN。
- 工程与通用性:Modality Agnostic (模态无关)
Transformer 带来了一个惊人的发现:只要你能把数据变成向量序列,我就能处理。
- NLP: 把句子切分为 Token 序列 进 Transformer。
- CV (Vision Transformer - ViT): 把图片切分为 的 Patch 序列 进 Transformer。
- Audio: 把音频频谱切分为片段序列 进 Transformer。
- Robotics (VLA): 把机器人动作(关节角度)变成 Token 序列 进 Transformer。
这种统一的接口,直接促成了现在的 多模态大模型 (Multimodal LLMs)。以前做视频、做图像、做文本需要三种不同的网络架构,现在一个 Transformer 全包了。
- 为什么需要位置编码
无论是rnn,cnn都能够直接获取到序列的前后顺序信息
但是transformer主干网络不能获取到,
所以采用位置编码,对输入进行修改,向模型提供 序列信息
- 根本原因:Transformer 是“脸盲”
假设我们要处理两个句子:
- Tom hit Jerry. (汤姆打了杰瑞)
- Jerry hit Tom. (杰瑞打了汤姆)
在 Transformer 的自注意力 (Self-Attention) 机制里,计算是并行的。 如果不加位置编码,模型看这两个句子是一模一样的:
- 它只知道句子里有
{Tom, hit, Jerry}这三个词。
- 它完全不知道谁在前面,谁在后面。
- 这就好比把你扔进一个房间,房间里有这三个人,但你不知道他们是谁先进来的。
结论: 如果没有位置信息,Transformer 就会变成一个“词袋模型”(Bag of Words),完全丢失语序信息。
- 解决方法:给数据“盖戳”
为了解决这个问题,我们在数据输入进模型之前,强制把位置信息加进去。
实际操作(数据层面)
位置编码不是一个额外的输入通道,而是直接修改了原始的词向量。
假设你的词向量维度是 4维(为了方便看):
- 原始词向量 (Input Embedding): 代表 "Tom" 的语义。
Vector_Tom = [0.2, 0.4, 0.1, 0.9]
- 位置向量 (Positional Vector): 这是一个通过数学公式(通常是 Sin/Cos 函数)生成的固定向量,专门用来代表 “第1个位置”。
Vector_Pos1 = [0.1, 0.0, 0.1, 0.0]
- 最终输入 (Final Input): 直接相加 (Element-wise Addition)。
Input = Vector_Tom + Vector_Pos1= [0.3, 0.4, 0.2, 0.9]
结果: 这个新的向量
[0.3, 0.4, 0.2, 0.9],既包含了 "Tom" 的含义(大部分数值来自词向量),又隐含了 "我是排在第一位" 的信息(因为被位置向量微调过)。datawhale-动图详解: https://github.com/datawhalechina/learn-nlp-with-transformers
检测问题:
1. 为什么注意力机制比传统 RNN 更适合长序列建模?
核心区别在于 “串行” vs “并行” 以及 信息传递的距离。
- RNN (递归神经网络) 的短板:
- 串行计算: 必须读完第一个字才能读第二个字,无法利用 GPU 并行加速。
- 遗忘问题(梯度消失): 信息像传话游戏,传递距离越远,丢失越严重。要理解第 100 个字和第 1 个字的关系,信息必须经过 99 次传递,几乎磨损殆尽。
- Attention (注意力机制) 的优势:
- 并行计算: 它可以同时处理整个句子,速度极快。
- 直连通道 (O(1) 路径): 无论句子多长,第 1 个字和第 100 个字之间的距离永远是 1。模型可以直接计算它们之间的相关性,瞬间捕捉长距离依赖。
2. 注意力机制里的 Query、Key、Value 分别起什么作用?
这三者模拟了**数据库查询(Retrieval)**的过程:
- Query (Q) —— 提问者/需求: 代表当前正在处理的词。它发出的信号是:“我想找和我相关的信息。”
- 例子:在翻译“它”这个词时,Q 代表“它”的向量,试图弄清“它”指代谁。
- Key (K) —— 索引/标签: 代表序列中所有词的特征标签。用于和 Q 进行匹配(点积计算相似度)。
- 例子:句子中其他词(如“猫”、“桌子”)的 K 向量,表明自己是名词、单数等特征。
- Value (V) —— 实际内容: 代表序列中所有词的具体信息。
- 作用:一旦 Q 和某个 K 匹配成功(分数高),模型就会把这个 K 对应的 V 提取出来,加权融合到结果中。
3. 多头注意力的好处是什么?
核心好处是**“多视角”和“防止过拟合”**。
- 捕捉多种特征 (不同的表示子空间): 如果只有一个头,模型可能只关注“语法关系”。有了多头(比如 8 个),模型可以并行分工:
- 头 1 关注 语法 (谁动作了谁)。
- 头 2 关注 指代 (it 指的是什么)。
- 头 3 关注 上下文 (积极还是消极)。
- 增强鲁棒性: 就像把鸡蛋放在不同的篮子里。即使某个头关注错了重点,其他头也能把信息补回来,保证最终理解的全面性。
4. Transformer 为什么不需要循环或卷积?
Transformer 用两套机制完美替代了 RNN 和 CNN 的功能:
- 替代 RNN (解决时序问题):使用“位置编码 (Positional Encoding)”。 RNN 靠按顺序输入来记录位置,Transformer 直接把位置信息(如“我是第1个”,“我是第2个”)加到词向量里。有了这个“戳”,模型即便并行输入也能分清先后,因此不需要循环。
- 替代 CNN (解决特征提取问题):使用“全局注意力 (Global Attention)”。 CNN 靠滑动窗口(卷积核)一点点看局部。Transformer 的注意力机制能一眼看到全局(Global Receptive Field)。它不需要通过堆叠卷积层来扩大视野,第一层就能把图像/句子看全,因此不需要卷积。