type
Post
status
Published
date
Dec 15, 2025 05:40
slug
summary
tags
diffusion-policy
imitation-learning
robotics
multimodal-control
category
工具
icon
password
文本
0. 元数据 (Meta Data)
- Title: Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
- Authors: Cheng Chi, Zhenjia Xu, et al. (Columbia University, Toyota Research Institute, MIT)
- Venue: RSS 2023 (Extended version tested here)
- Tags: #DiffusionModel #ImitationLearning #Robotics #MultimodalControl
- One-Liner: 将机器人的视觉运动策略建模为条件去噪扩散过程,通过学习动作分数的梯度场,解决了模仿学习中多模态分布拟合难和高维动作序列预测不稳定的核心问题。
1. 核心痛点与动机 (The "Why")
Context: 在这篇论文出来之前,行为克隆(Behavior Cloning)领域存在着“多模态噩梦”和“训练稳定性”的两难选择。
- [痛点 1:多模态分布崩塌 (The Multimodal Trap)]:
- 现状/缺陷: 传统显式策略(Explicit Policy,如 MSE 回归)倾向于输出演示数据的平均值。
- 比喻/洞见: 这就像**“布里丹之驴”**。如果人类演示数据里既有“从左边推物体”,又有“从右边推物体”,MSE 训练出来的模型会选择走中间——结果直接撞在物体上。现有的解决方案如混合高斯模型(GMM)或分类法(Discretization)在高维空间中参数难以调整,且精度受限。
- [痛点 2:隐式策略的训练黑洞 (Implicit Policy Instability)]:
- 现状: 隐式策略(如 IBC - Implicit Behavioral Cloning)虽然理论上能处理多模态,通过优化能量函数(Energy Function)来选择动作。
- 缺陷: 训练极其不稳定。IBC 需要负采样来估计配分函数(Partition Function),这不仅计算昂贵,而且对超参数极度敏感,经常出现训练 Loss 下降但推理成功率极低的情况。这就像**“在黑暗中射箭”**,很难知道模型到底学没学会。
- [痛点 3:时序一致性差 (Lack of Temporal Consistency)]:
- 现状: 单步预测的模型容易出现动作抖动(Jittery),缺乏流畅性,且容易因观测延迟而失效。
2. 核心创新点 (The "How")
Context: Diffusion Policy 是如何降维打击上述痛点的?它并没有发明扩散模型,而是极其巧妙地将其适配到了控制领域。
2.1 输入输出流 (I/O Stream)
- Input (感知端):
- 视觉: 图像序列 (通常包含多个视角,使用 ResNet-18 + Spatial Softmax 编码)。
- 状态: 机器人关节角度等本体感知信息。
- Output (动作端):
- 形式: 位置控制 (Position Control) 优于速度控制。这是一个反直觉的发现,因为大多数 BC 方法偏好速度控制。Diffusion Policy 利用其强大的分布拟合能力,使得位置控制的高精度优势得以发挥,避免了速度控制的累积误差。
- 频率/视野: 预测未来 步的动作序列(Action Sequence),例如预测 16 步,但只执行前 8 步(Receding Horizon Control)。
2.2 核心模块与选择原因 (Module & Selection)
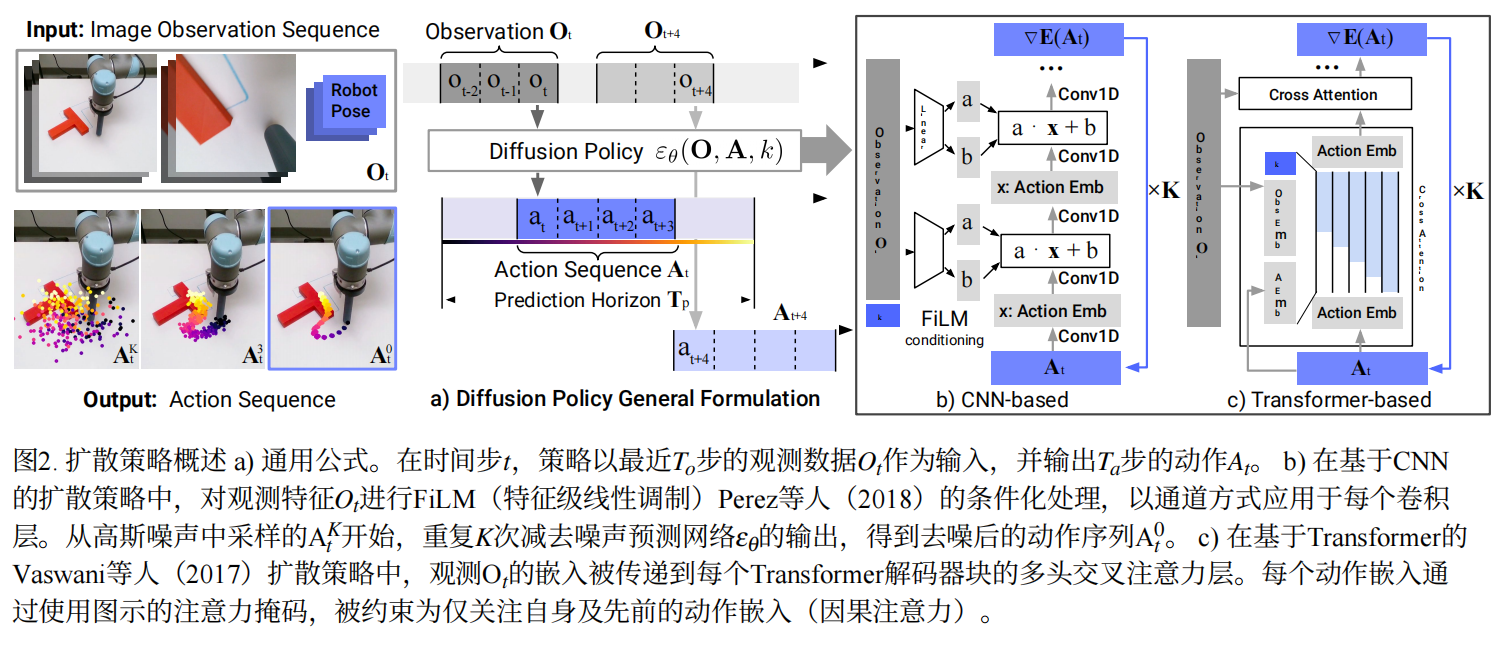
- 核心模块 A: 条件去噪扩散过程 (Conditional DDPM)
- 选择理由: Diffusion 本质上是在学习动作分布的梯度场(Score Function)。与 IBC 不同,它不需要计算那个难缠的归一化常数(Partition Function),直接对梯度进行建模。
- 带来的收益: 这种方式完美继承了扩散模型生成高质量图像的能力——在这里就是生成高维、多模态、高精度的动作轨迹。它能够自然地表达“既可以左推也可以右推”的分布,而不会取平均值。
- 核心模块 B: 滚动视界控制 (Receding Horizon Control)
- 机制: 模型一次预测 步动作,执行 步,然后重新规划。
- 比喻: 这就像**“老司机开车”**,目光永远看着前方一段路(预测序列),而不是只盯着脚下的油门(单步预测)。这不仅保证了动作的平滑性(Temporal Consistency),还极大地提升了对延迟(Latency)的鲁棒性,甚至能抵抗图像传输的滞后。
- 核心模块 C: 视觉调节 (Visual Conditioning)
- 策略: 视觉特征 仅作为条件输入,而不参与去噪迭代过程。
- 收益: 这种解耦设计让视觉编码器只需要运行一次,而不是在每步去噪(比如 K=10 步)中都运行,大幅降低了推理计算量,实现了实时控制。
3. 数据策略与创新 (Data Strategy)
重点在于模型对“不完美数据”的消化能力。
- 数据集构成: 涵盖了 4 个 Benchmark 的 15 个任务,包括 Robomimic (Proficient/Mixed Human data), Kitchen, Push-T 等,包含刚体和流体操作。
- 创新点 (Tolerance to Idle Actions):
- 描述: 人类演示中经常包含“发呆”或“等待”动作(Idle actions),例如倒水时等待液体流出。传统方法(如 LSTM-GMM)容易过拟合这些静止动作导致卡死。
- 收益: 由于 Diffusion Policy 预测的是动作序列(Action Chunk),它能理解“静止”是长序列的一部分,从而自然地完成倒水等需要短暂停顿的任务,而不需要像传统方法那样在预处理中剔除静止数据。
- 鲁棒性验证: 甚至在训练数据没有覆盖的情况下,模型展现出了对物理扰动(如移动目标物体)的即时反应能力,这得益于其快速的闭环重规划能力。
4. 评测与本质分析 (Evaluation & Comparison)
需要说明使用了什么机器/仿真环境进行评测
基于什么数据集
基于什么benchmark,是否有创新
Diffusion Policy 不是险胜,而是碾压。
- 总体表现: 在 15 个任务中平均提升成功率 46.9%。
- SOTA 深度对比 (Critical Comparison):
- Vs. IBC (Implicit Behavioral Cloning):
- 核心差异: IBC 优化能量函数,Diffusion 优化梯度场。
- 胜出逻辑: 训练稳定性。IBC 的训练曲线经常震荡,检查点选择极其困难(Needle in a haystack);而 Diffusion Policy 的训练非常稳定,不需要复杂的超参数调优就能收敛。
- Vs. LSTM-GMM / BET:
- 核心差异: LSTM-GMM 用高斯混合模型拟合多模态;BET 使用 K-means 聚类离散化动作。
- 胜出逻辑: 多模态承诺 (Mode Commitment)。在 Push-T 任务中,LSTM-GMM 倾向于在两个模式间偏差(bias),BET 无法锁定一个模式导致犹豫;而 Diffusion Policy 能像人类一样,坚定地选择“左边”或“右边”的一条完整轨迹执行到底。
- Vs. 速度控制基线 (Velocity Control Baselines):
- 核心差异: 现有 SOTA 大多依赖速度控制来规避位置控制的突变问题。
- 胜出逻辑: 高精度位置控制。Diffusion Policy 证明了使用位置控制(Position Control)效果远好于速度控制。因为它能生成平滑的序列,不仅精度更高,而且不受累积误差影响。
5. 关键术语对照 (Key Terms)
- DDPM (Denoising Diffusion Probabilistic Models): 去噪扩散概率模型,本文的核心生成基座。
- Receding Horizon Control (滚动视界控制): 预测未来一段序列,只执行前几步,然后重新预测。用于平衡长期规划和平滑性。
- FiLM (Feature-wise Linear Modulation): 一种特征调节机制,用于将视觉特征注入到 CNN Backbone 中。
- Action Score Function: 动作分数函数,即动作分布对数密度的梯度 ,Diffusion Policy 实际上是在学习这个梯度场。
- Temporal Action Consistency: 时序动作一致性,指动作序列之间平滑连贯,不会出现高频抖动。
6. 总结 (Takeaway)
Diffusion Policy 是一篇里程碑式的论文,它通过引入扩散模型,优雅地解决了机器人模仿学习中长期存在的多模态分布拟合和高维动作序列预测难题。
核心 Insight:
- 梯度优于能量: 学习 Score Function(梯度)比直接学习 Energy Function(如 IBC)要稳定得多。
- 序列优于单步: 预测 Action Sequence + 滚动执行,是解决抖动、提升精度和抗延迟的关键。
- 位置优于速度: 当模型足够强大(能拟合复杂分布)时,位置控制能提供比速度控制更高的操作上限。
它不仅刷新了 SOTA,更重要的是它证明了生成式模型(Generative Models)在决策控制领域同样具有统治力,为后续基于 Transformer 的大规模机器人策略(如后续的各类 Policy)铺平了道路。
7.reference
flow-matching
diffusion model是从噪声转换成图像
t表示噪声有无
t=1表示无噪声
diffusion model training
在forward diffusion step
通过高斯函数给图像每个像素加噪声




现在才是模型训练的正式环节,依据之前的forward diffusion
训练一个神经网络图像和t作为输入,经常是transformer model,这个模型可以根据图像输出当前噪点的程度

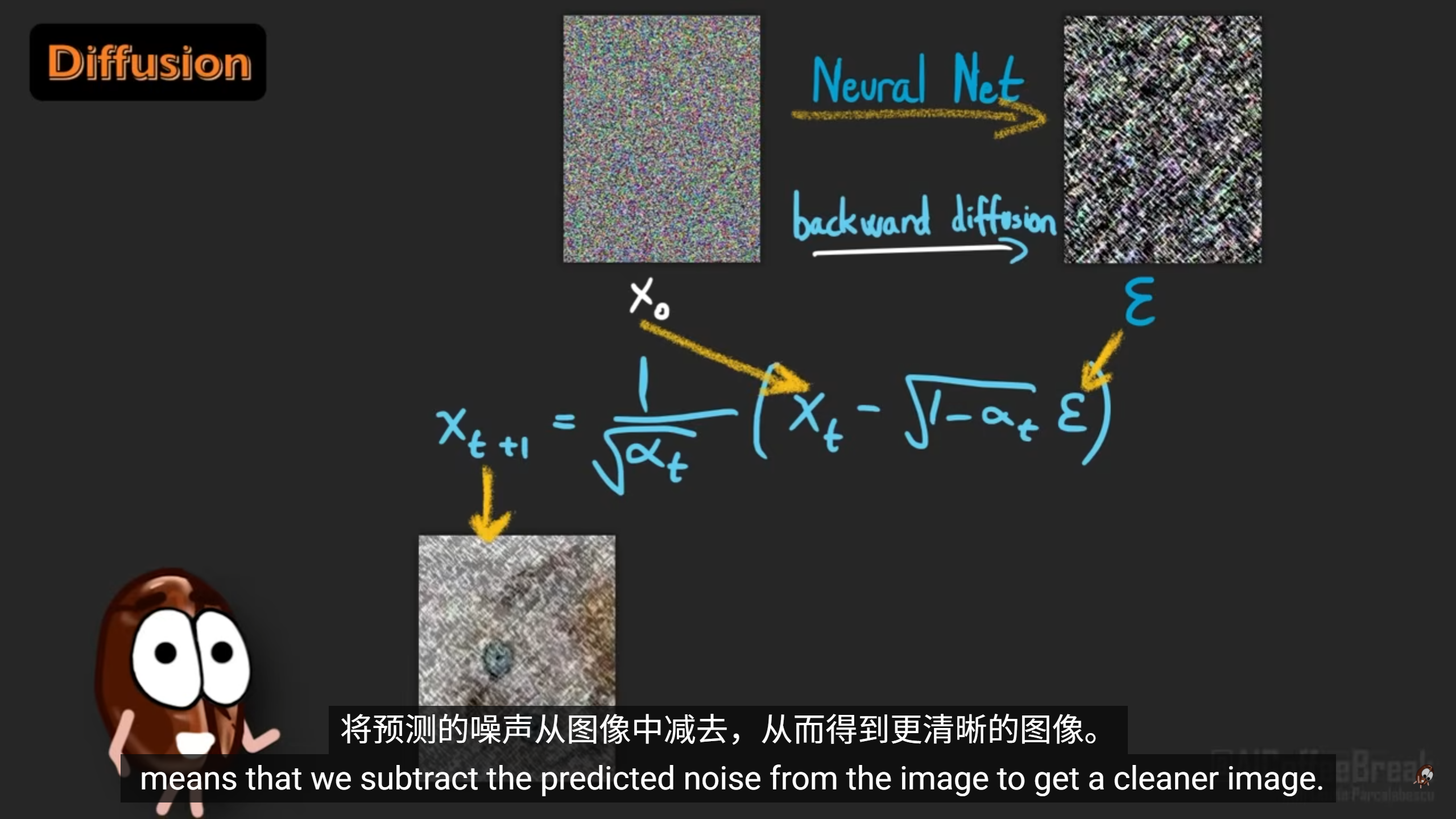
然后逆解高斯函数,就能通过带噪点的图像,反向得出清晰的图像。
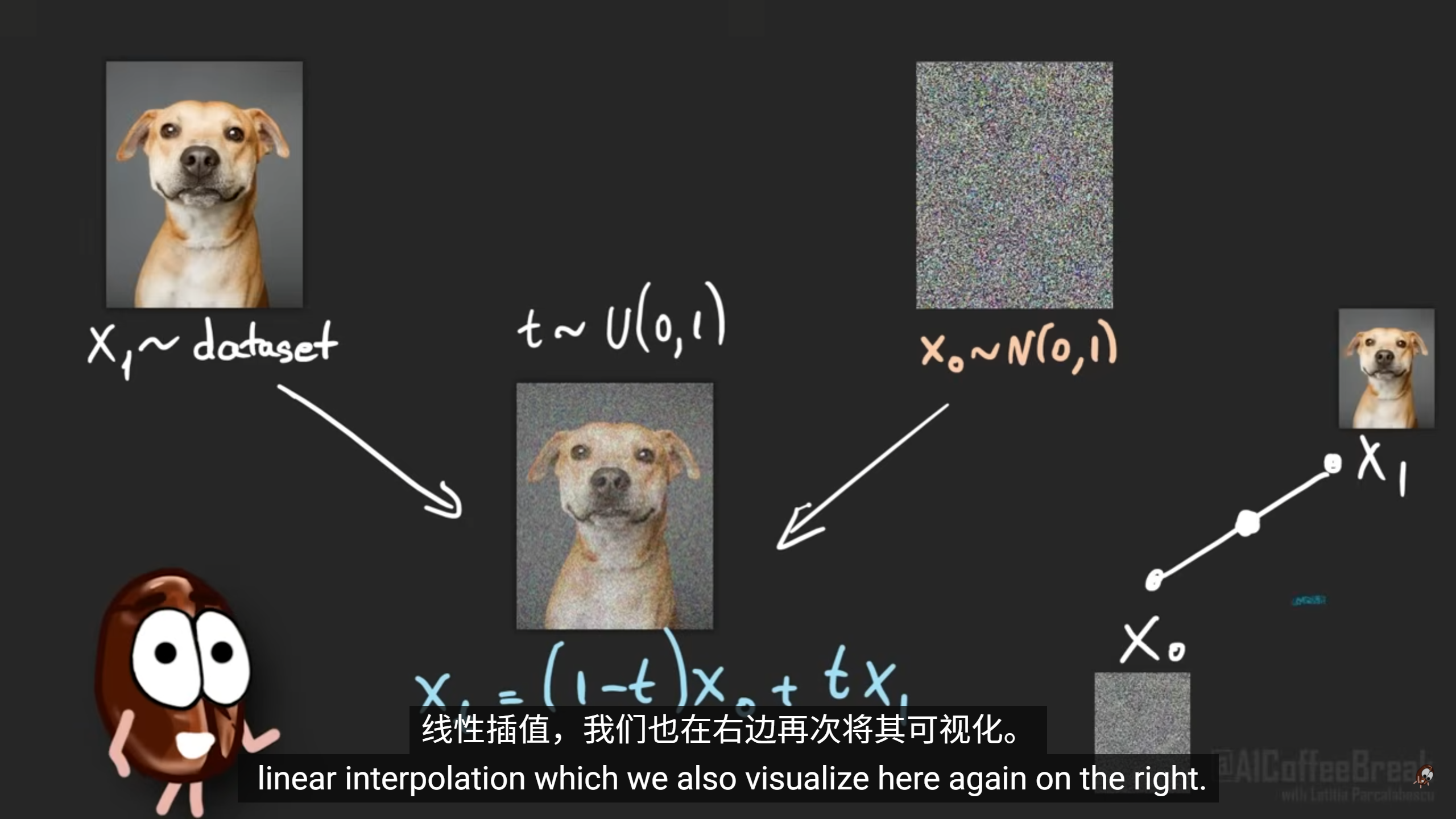
流匹配就是将去掉高斯函数,
只利用速度场


利用全模糊和不模糊,线性预测t=0.5
直接获取线性插值
看不懂,总结为利用多张图片来直接进行模型调参,让模型能够对图像进行加噪或者去噪
选择数据集中的一张图片,然后挑一张加噪图片,利用这两张图片进行模型调参
而diffussion model只有利用加噪图像