type
Post
status
Published
date
Dec 15, 2025 05:46
slug
summary
tags
pi0
robotics
VLA
flow-matching
category
工具
icon
password
文本
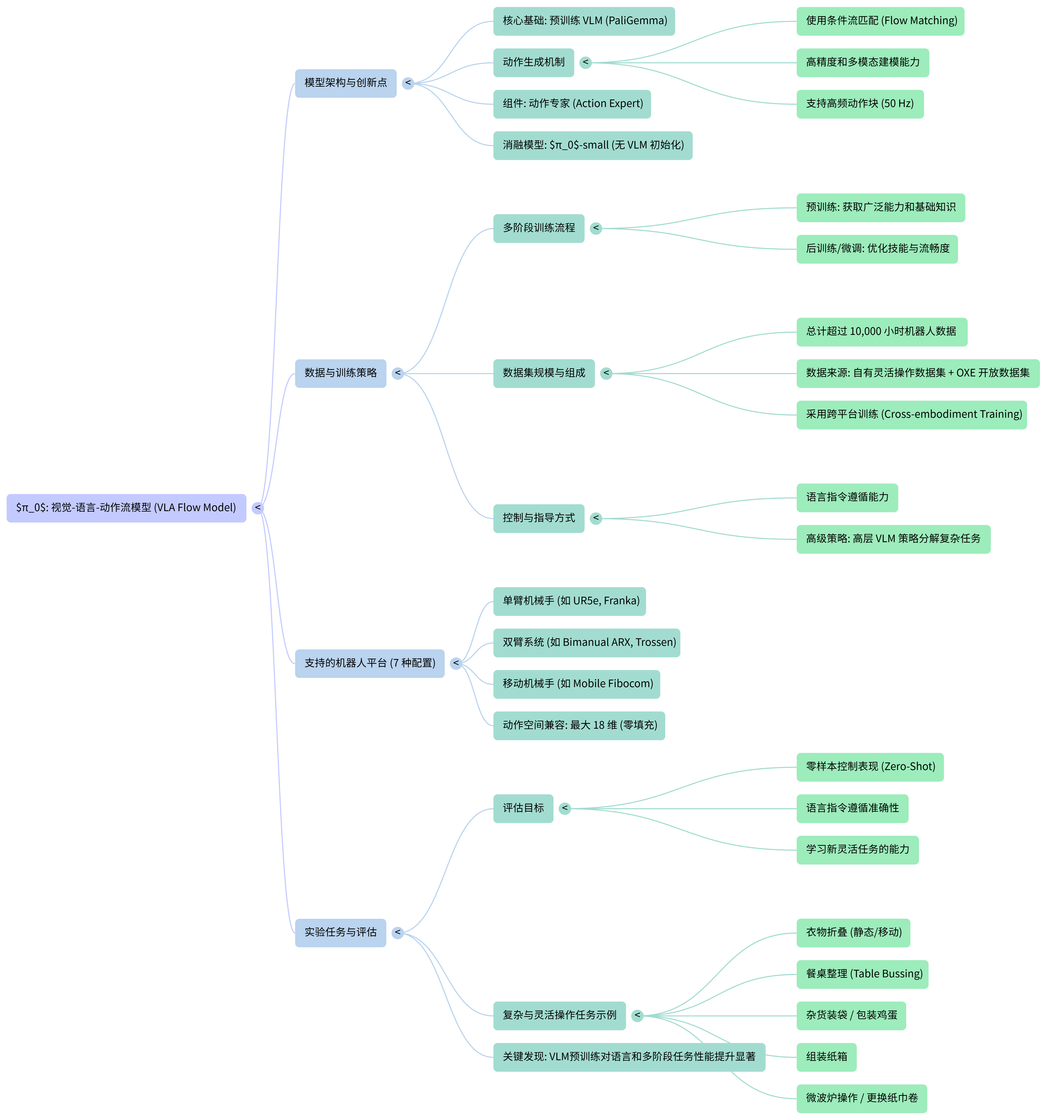
0. 元数据 (Meta Data)
- Title: : A Vision-Language-Action Flow Model for General Robot Control
- Authors: Kevin Black, Noah Brown et al. (Physical Intelligence)
- Venue: arXiv 2024 / Physical Intelligence Blog
- Tags: #VLA #FlowMatching #RobotFoundationModel #DexterousManipulation #CrossEmbodiment
- One-Liner: 将 3B 参数的 VLM (PaliGemma) 与基于 Flow Matching 的动作专家结合,利用 10,000 小时跨机器人数据,构建了一个兼具语义理解与高频精细操作能力的通用机器人基座模型。
1. 核心痛点与动机 (The "Why")
Context: 在这篇论文出来之前,具身智能领域存在“脑子好使手笨”与“手巧脑子不灵”的割裂。
- 通用性与灵巧性的权衡 (Versatility-Dexterity Trade-off):
- 现状/缺陷: 现有的通用机器人策略(如 RT-2, OpenVLA)通常基于离散化的 Token 预测动作,这种方式难以处理高频(如 50Hz)、高精度的连续动作控制,导致“手很笨”。而专门针对灵巧操作的模型(如 ACT, Diffusion Policy)通常只能在特定任务上训练,缺乏泛化能力,稍微换个物体或场景就失效。
- 比喻/洞见: 现有的 VLA 模型就像是一个“坐在轮椅上的哲学家”,读过互联网万卷书(语义理解强),但让他去穿针引线或叠衣服(物理交互)时,因为动作输出是离散的“词语”,动作就像机器人跳机械舞一样僵硬,无法完成细腻的物理操作。
- 数据利用的瓶颈 (Data Scarcity & Utilization):
- 现状: 高质量的灵巧操作数据极度稀缺,且单一机器人的数据难以支撑大模型的“胃口”。
- 需求: 需要一种架构,既能像“大胃王”一样消化互联网上的多模态数据(VLM预训练),又能利用来自不同形态机器人(单臂、双臂、移动底盘)的杂乱数据进行跨具身(Cross-Embodiment)学习。
2. 核心创新点 (The "How")
Context: 是如何缝合 VLM 的大脑与 Flow Matching 的小脑的?
2.1 输入输出流 (I/O Stream)
- Input (感知端):
- 视觉: 多视角 RGB 图像(根据机器人配置,最多 3 个摄像头:左右腕部 + 基座)。
- 状态: 语言指令(Language Command) + 机器人本体感知状态(关节角度 )。
- Output (动作端):
- 形式: 连续的动作块(Action Chunking),一次预测未来 步的动作分布。
- 频率: 支持高达 50Hz 的高频控制,适应高动态任务。
2.2 核心模块与选择原因 (Module & Selection)
- 架构设计: VLM Backbone + Action Expert (MoE Style)
- VLM Backbone (PaliGemma 3B):
- 选择理由: 利用其预训练的互联网级语义知识和推理能力,作为系统的“大脑”。
- Action Expert (Flow Matching):
- 选择理由: 这是一个基于 Flow Matching(类 Diffusion)的模块,参数量约 300M。相比于 VLM 常用的自回归离散输出,Flow Matching 能精准建模连续、多模态的动作分布,相当于给大脑配了一个精密的“小脑”来负责具体的肌肉控制。
- 弃用方案: 相比于 OpenVLA 的离散 Token 方案,Flow Matching 避免了离散化带来的精度损失和低频问题;相比于纯 Diffusion Policy,它通过 VLM 注入了强大的语义引导。
3. 数据策略与创新 (Data Strategy)
Data is the new code. 的成功很大程度上归功于其类似 LLM 的训练配方。
- 数据集构成:
- 总规模: 约 10,000 小时的机器人操作数据,是目前已知最大的机器人学习实验之一。
- 来源: 包含 Open X-Embodiment (9.1%) 以及自采集的 7 种不同机器人构型(单/双臂、移动/固定基座)的 68 种任务数据。
- 创新点 (Innovation):
- 预训练/后训练分离 (Pre-training/Post-training Recipe): 模仿 LLM 的训练范式。
- 预训练阶段: 使用大规模、多样化(但也包含低质量)的数据混合。目的是让模型“见多识广”,学会从错误中恢复,具备鲁棒性。
- 后训练阶段 (SFT): 使用少量、高质量的精选数据进行微调。目的是让模型学会“举止优雅”,掌握高效、流畅的操作策略。
- 带来的收益 (Benefit):
- 预训练赋予了模型在零样本(Zero-shot)情况下的基础能力和鲁棒性;后训练则让模型能够完成如“叠衣服”、“组装纸箱”等极其复杂的长程任务。
4. 评测与本质分析 (Evaluation & Comparison)
不仅分数高,更重要的是它能做别的模型做不了的事。
- 胜出关键: 在长程、高灵巧度任务(如叠衣服、清理餐桌、组装箱子)上表现卓越,能够处理不同构型(单臂 vs 双臂)的机器人控制。
- SOTA 深度对比 (Critical Comparison):
- Vs. OpenVLA:
- 核心差异: OpenVLA 输出离散的 Action Token,不支持 Action Chunking; 使用 Action Expert 输出连续动作流,支持 50Hz Action Chunking。
- 胜出逻辑: OpenVLA 的离散化导致其无法进行高频精细操作(如叠衣服时的微调),在 Zero-shot 评测中, 在所有任务上大幅领先 OpenVLA,尤其是在需要连续轨迹控制的任务上。
- Vs. Octo:
- 核心差异: Octo 是一个小参数量(93M)的 Diffusion Policy; 是拥有 3B 参数 VLM Backbone 的大模型。
- 胜出逻辑: 的“脑容量”更大(VLM Backbone),具有更强的语义泛化能力。在同等数据训练下, 的表现优于 Octo,证明了将大模型与动作生成结合的有效性。
- Vs. ACT / Diffusion Policy:
- 核心差异: 这些通常是 Train from Scratch 的小模型。
- 胜出逻辑: 利用了预训练的优势。在微调实验中, 即使在只有少量数据(如 1-5 小时)的情况下,依靠预训练的底座,通常比从头训练的 ACT/DP 表现更好,特别是在与预训练数据分布有差异的新任务上。
5. 关键术语对照 (Key Terms)
- Flow Matching: 一种生成模型技术,可视作 Diffusion 的一种变体,通过学习向量场将噪声分布映射到数据分布,用于生成连续动作。
- Action Chunking: 一次性预测未来一段固定长度(如 50 步)的动作序列,而不是每步预测一个。这对解决动作的不平滑和卡顿至关重要。
- Cross-Embodiment Training: 跨具身训练,即用一个模型同时控制不同形态的机器人(如 UR5e 和 Franka),通过统一动作空间(Padding)来实现。
6. 总结 (Takeaway)
是具身智能领域的 GPT-3 时刻之前的关键一步。它有力地证明了 "VLM 大脑 + Flow Matching 小脑" 的混合架构,配合 "大规模预训练 + 高质量后训练" 的数据配方,是通往通用机器人策略的可行路径。它不仅解决了以往 VLA 模型“手笨”的问题,还展示了通过数据规模化(Scaling)解决复杂物理任务(如叠衣服、组装)的潜力,标志着机器人学习正从“小作坊式的模仿学习”向“工业级的基座模型”迈进。